一. 类/函数组件在hooks出现前后的对比
1.为什么需要Hook
Hook是React 16.8的新增特性,它可以让我们在不编写class的情况下使用state以及其他的React特性(比如生命周期)我们先来思考一下**
class组件相对于函数式组件的优势**?比较常见的是下面的优势:class组件可以定义自己的state,用来保存组件自己内部的状态- 函数式组件不可以,因为函数每次调用都会产生新的临时变量
class组件有自己的生命周期,我们可以在对应的生命周期中完成自己的逻辑- 比如在
componentDidMount中发送网络请求,并且该生命周期函数只会执行一次 - 函数式组件在学习
hooks之前,如果在函数中发送网络请求,意味着每次重新渲染都会重新发送一次网络请求
- 比如在
class组件可以在状态改变时只会重新执行render函数以及我们希望重新调用的生命周期函数componentDidUpdate等- 函数式组件在重新渲染时,整个函数都会被执行,似乎没有什么地方可以只让它们调用一次
所以,在
Hook出现之前,对于上面这些情况我们通常都会编写class组件在·而函数式组件,一般用来做
ui组件的,没有自己内部的一些state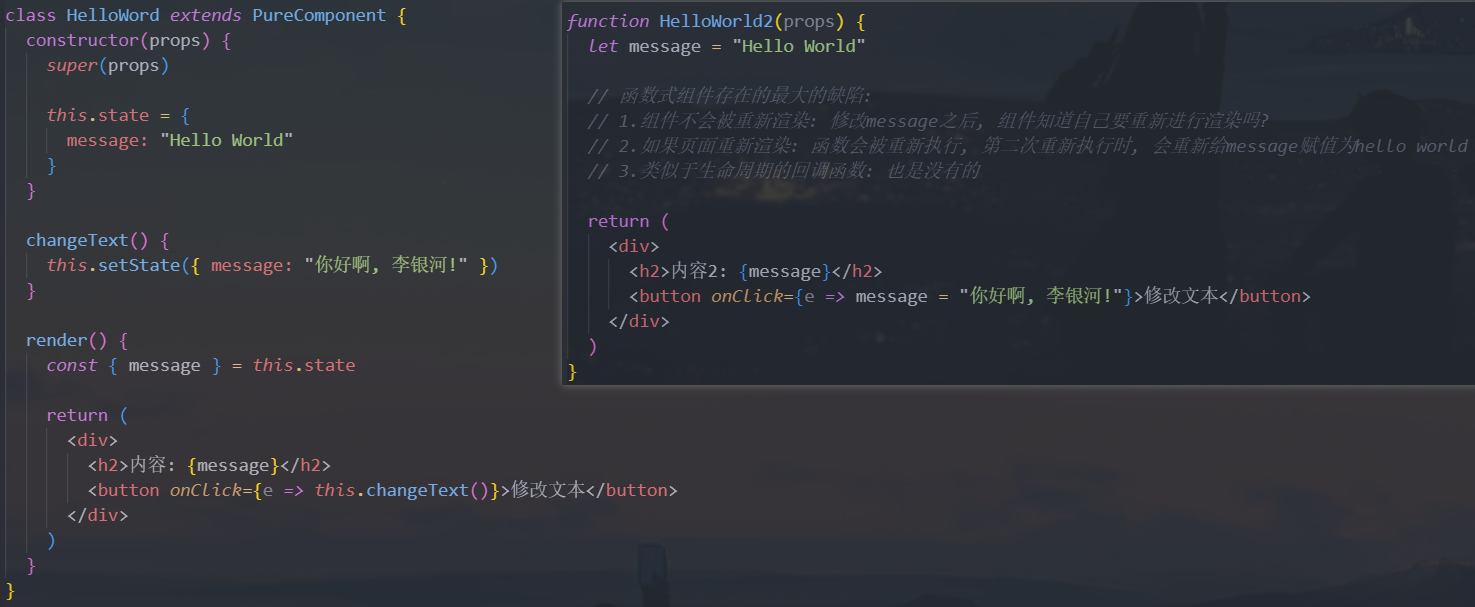
2.Class组件存在的问题
- 复杂组件变得难以理解:
- 我们在最初编写一个
class组件时,往往逻辑比较简单,并不会非常复杂。但是随着业务的增多,我们的class组件会变得越来越复杂 - 比如
componentDidMount中,可能就会包含大量的逻辑代码:包括网络请求、一些事件监听(还需要在componentWillUnmount中移除) - 而对于这样的
class实际上非常难以拆分:因为它们的逻辑往往混在一起,强行拆分反而会造成过度设计,增加代码的复杂度
- 我们在最初编写一个
- 难以理解的
class:- 很多人发现学习
ES6的class是学习React的一个障碍 - 比如在
class中,我们必须搞清楚this的指向到底是谁,所以需要花很多的精力去学习this - 虽然我认为前端开发人员必须掌握
this,但是依然处理起来非常麻烦
- 很多人发现学习
- 组件复用状态很难:
- 在前面为了一些状态的复用我们需要通过高阶组件
- 像我们之前学习的
redux中connect或者react-router中的withRouter,这些高阶组件设计的目的就是为了状态的复用 - 或者类似于
Provider、Consumer来共享一些状态,但是多次使用Consumer时,我们的代码就会存在很多嵌套 - 这些代码让我们不管是编写和设计上来说,都变得非常困难
3.Hook的出现
Hook的出现,可以解决上面提到的这些问题- 简单总结一下
hooks:- 它可以让我们在不编写
class的情况下使用state以及其他的React特性 - 但是我们可以由此延伸出非常多的用法,来让我们前面所提到的问题得到解决
- 它可以让我们在不编写
Hook的使用场景:Hook的出现基本可以代替我们之前所有使用class组件的地方- 官方:但是如果是一个旧的项目,你并不需要直接将所有的代码重构为
Hooks,因为**hooks完全向下兼容**,你可以渐进式的来使用它 Hook只能在函数组件中使用,不能在类组件,或者函数组件之外的地方使用
- 在我们继续之前,请记住
Hook是:- 完全可选的**:**你无需重写任何已有代码就可以在一些组件中尝试
Hook。但是如果你不想,你不必现在就去学习或使用Hook - 100%向后兼容的:
Hook不包含任何破坏性改动 - 现在可用:
Hook发布于v16.8.0
- 完全可选的**:**你无需重写任何已有代码就可以在一些组件中尝试
4.class组件和函数式组件结合hooks的对比
我们通过一个计数器案例,来对比一下
class组件和函数式组件结合hooks的对比: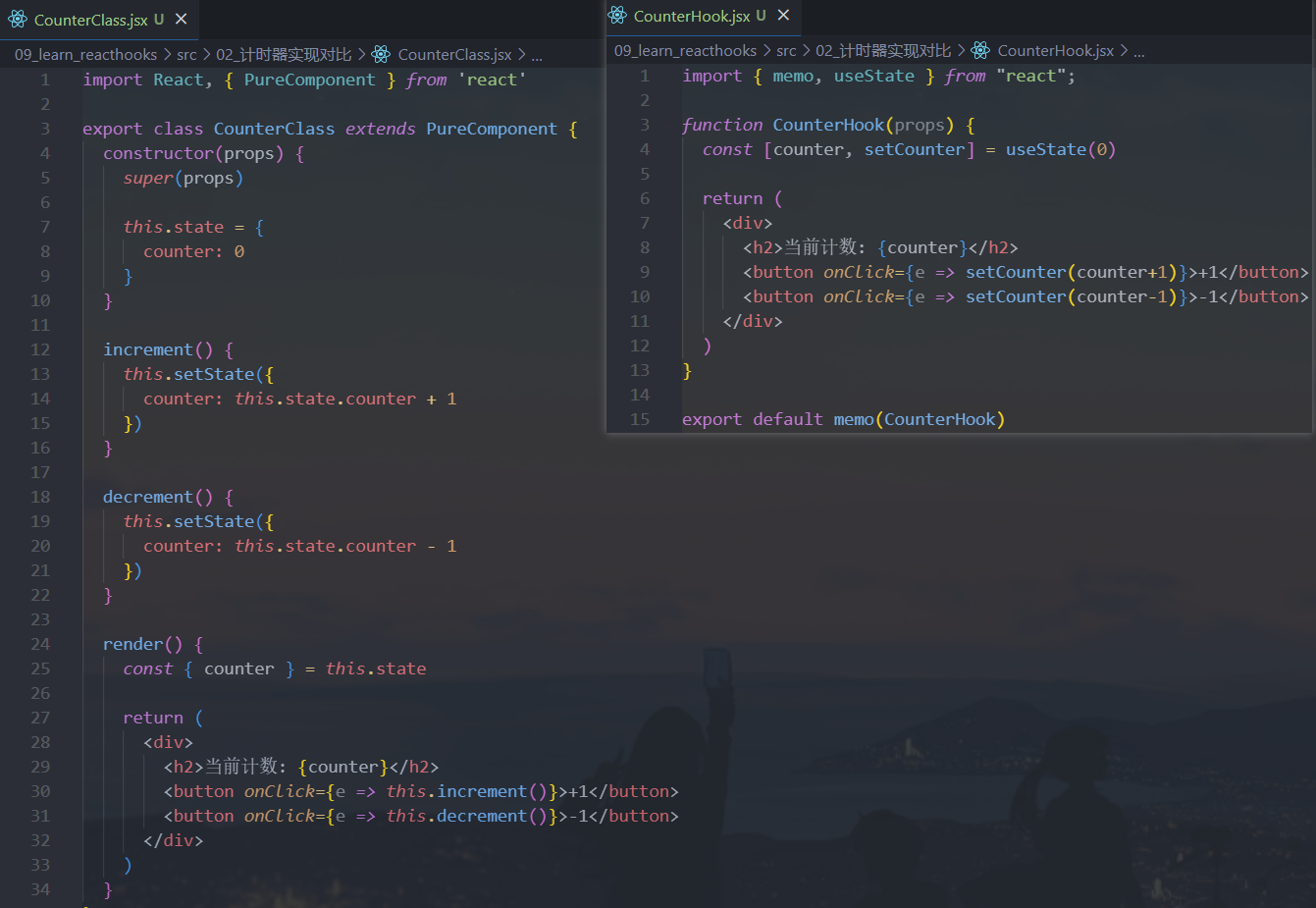
会发现上面的代码差异非常大:
- 函数式组件结合
hooks让整个代码变得非常简洁 - 并且再也不用考虑
this相关的问题
- 函数式组件结合
二. State/Effect
1.useState解析
useState来自react,需要从react中导入,它是一个hook(钩子函数)- 参数:初始化值,如果不设置,则为
undefined - 返回值:数组,包含两个元素
- 元素一:当前状态的值(第一次调用,为初始化值,之后都是该状态上一次设置的值)
- 元素二:设置状态值的函数,调用后,整个函数组件会被重新执行
- 点击
button按钮后,会完成两件事情:- 调用
setCount,设置一个新的值 - 组件重新渲染,并且根据新的值返回
DOM结构
- 调用
- 参数:初始化值,如果不设置,则为
Hook就是js函数,这个函数可以帮助你 钩入(hook into)React State以及生命周期等特性- 个人理解:就是给你保存某个状态,然后在使用的时候,可以获取到该状态
- 但是使用它们会有两个额外的规则:
- 只能在函数最外层调用
Hook,不能在循环、条件判断、子函数中调用 - 只能在
React的函数组件中调用Hook,或以use开头命名的其他js函数
- 只能在函数最外层调用
Tip:Hook指的类似于useState、useEffect这样的函数Hooks是对这类函数的统称hook可以在自定义hook中使用,自定义hook必须以use开头进行命名
2.认识useState
State Hook的API就是useState,我们在前面已经进行了学习:useState会帮助我们定义一个state变量,useState是一种新方法,它与class里面的this.state提供的功能完全相同- 一般来说,在函数执行完成之后,变量就会”消失”,而
state中的变量会被React保留
- 一般来说,在函数执行完成之后,变量就会”消失”,而
useState接受唯一 一个参数,在第一次组件被调用时使用来作为初始化值。(如果没有传递参数,那么初始化值为undefined)- 如果传入的是一个函数,函数的返回值会被作为初始化值
useState的返回值是一个数组,我们可以通过数组的解构,来完成赋值会非常方便https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Operators/Destructuring_assignment
FAQ:为什么叫useState而不叫createState?- “
create” 可能不是很准确,因为state只在组件首次渲染的时候被创建 - 在下一次重新渲染时,
useState返回给我们当前的state - 如果每次都创建新的变量,它就不是 “
state”了 - 这也是
Hook的名字总是以use开头的一个原因
- “
- 当然,我们也可以在一个组件中定义多个变量和复杂变量(数组、对象)
- 个人总结:
- 在组件初始化渲染的时候,useState传入的初始值才会生效,后续组件重新渲染的时候,传入的初始值不会生效
- 修改
useState返回的数组中的第一个值,必须要使用返回的数组中的第二个值setxxx函数,才能进行修改
3.认识Effect Hook
目前我们已经通过
hook在函数式组件中定义state,那么类似于生命周期这些呢?Effect Hook可以让你来完成一些类似于class中生命周期的功能- 事实上,类似于网络请求、手动更新
DOM、一些事件的监听,都是React更新DOM的一些副作用(Side Effects) - 所以对于完成这些功能的
Hook被称之为Effect Hook
useEffect的解析:- 通过
useEffect的Hook,可以告诉React需要在渲染后执行某些操作 useEffect要求我们传入一个回调函数,在React执行完更新DOM操作之后,就会回调useEffect中传入的这个函数- 默认情况下,无论是第一次渲染之后,还是每次更新之后,都会执行这个回调函数
- 通过
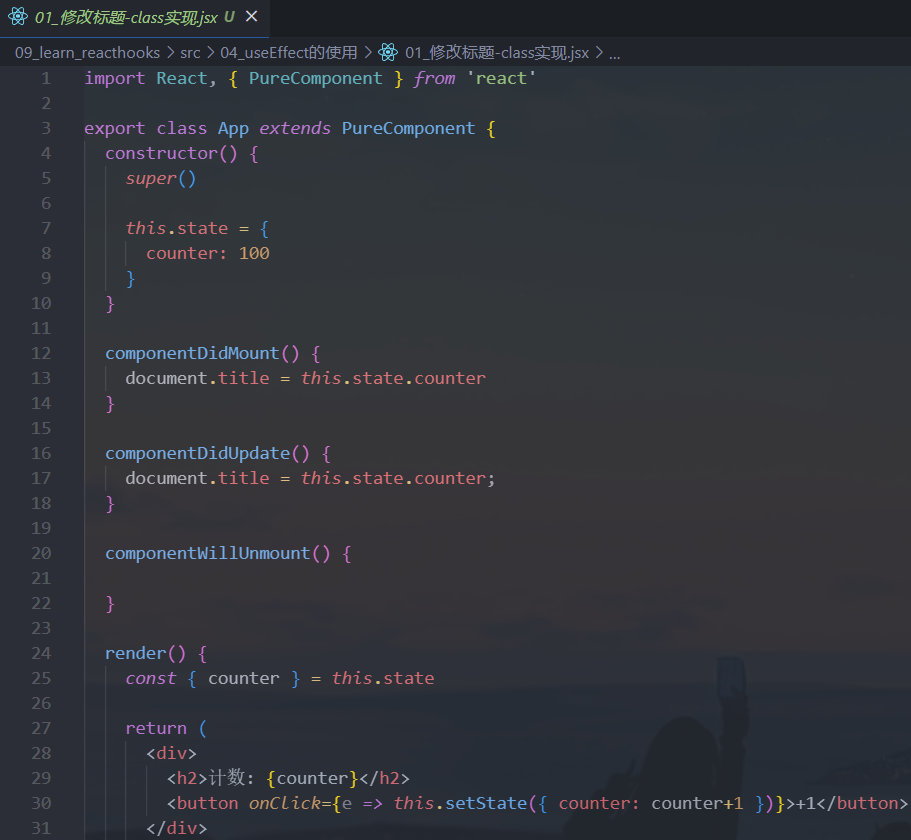
假如我们现在有一个需求:页面的
title总是显示counter的数字,分别使用class组件和Hook实现: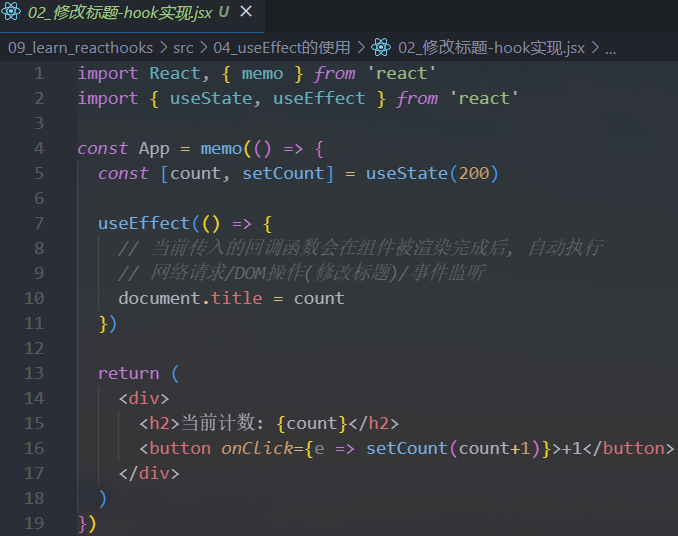
4.需要清除Effect
在
class组件的编写过程中,某些副作用的代码,我们需要在componentWillUnmount中进行清除:- 比如我们之前的事件总线 或
Redux中手动调用subscribe - 都需要在
componentWillUnmount有对应的取消订阅 Effect Hook通过什么方式来模拟componentWillUnmount呢?
- 比如我们之前的事件总线 或
useEffect传入的回调函数本身可以有一个返回值,这个返回值是另外一个回调函数:typescripttype EffectCallback = () => (void | (() => void | undefined))为什么要在
effect中返回一个函数?- 这是
effect可选的清除机制。每个effect都可以返回一个清除函数 - 如此可以将添加和移除订阅的逻辑放在一起
- 它们都属于
effect的一部分
- 这是
React何时清除effect?React会在组件更新和卸载的时候执行effect清除操作(即执行返回函数)正如之前学到的,
effect在每次渲染的时候都会执行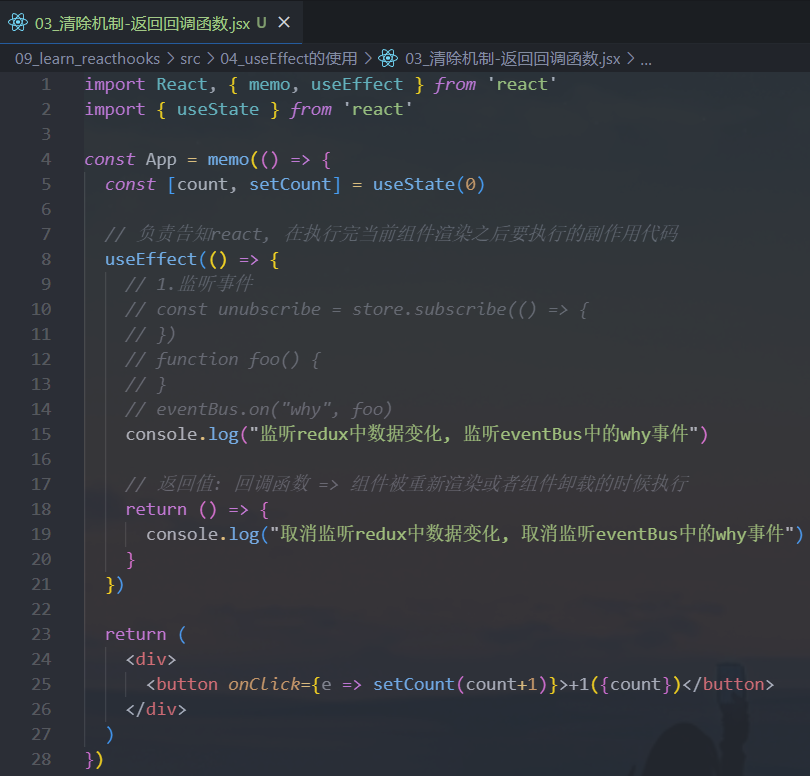
5.使用多个Effect
使用
Hook的其中一个目的就是解决class中生命周期经常将很多的逻辑放在一起的问题:- 比如网络请求、事件监听、手动修改
DOM,这些往往都会放在componentDidMount中
- 比如网络请求、事件监听、手动修改
使用
Effect Hook,我们可以将它们分离到不同的useEffect中:Hook允许我们按照代码的用途分离它们,而不是像生命周期函数那样:React将按照effect声明的顺序依次调用组件中的每一个effect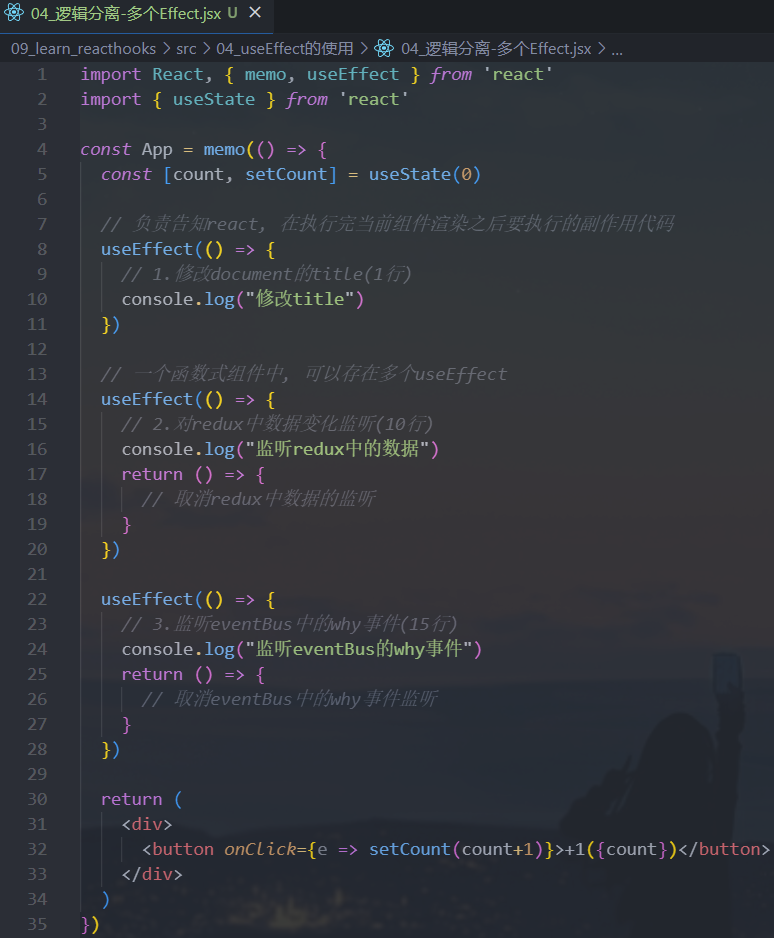
6.Effect性能优化
默认情况下,
useEffect的回调函数会在每次渲染时都重新执行,但是这会导致两个问题:- 某些代码我们只是希望执行一次即可,类似于
componentDidMount和componentWillUnmount中完成的事情(比如网络请求、订阅和取消订阅) - 另外,多次执行也会导致一定的性能问题
- 某些代码我们只是希望执行一次即可,类似于
我们如何决定
useEffect在什么时候应该执行和什么时候不应该执行呢?useEffect实际上有两个参数:- 参数一:执行的回调函数
- 参数二:该
useEffect在哪些state发生变化时,才重新执行(受谁的影响)
案例练习:
受
count影响的Effect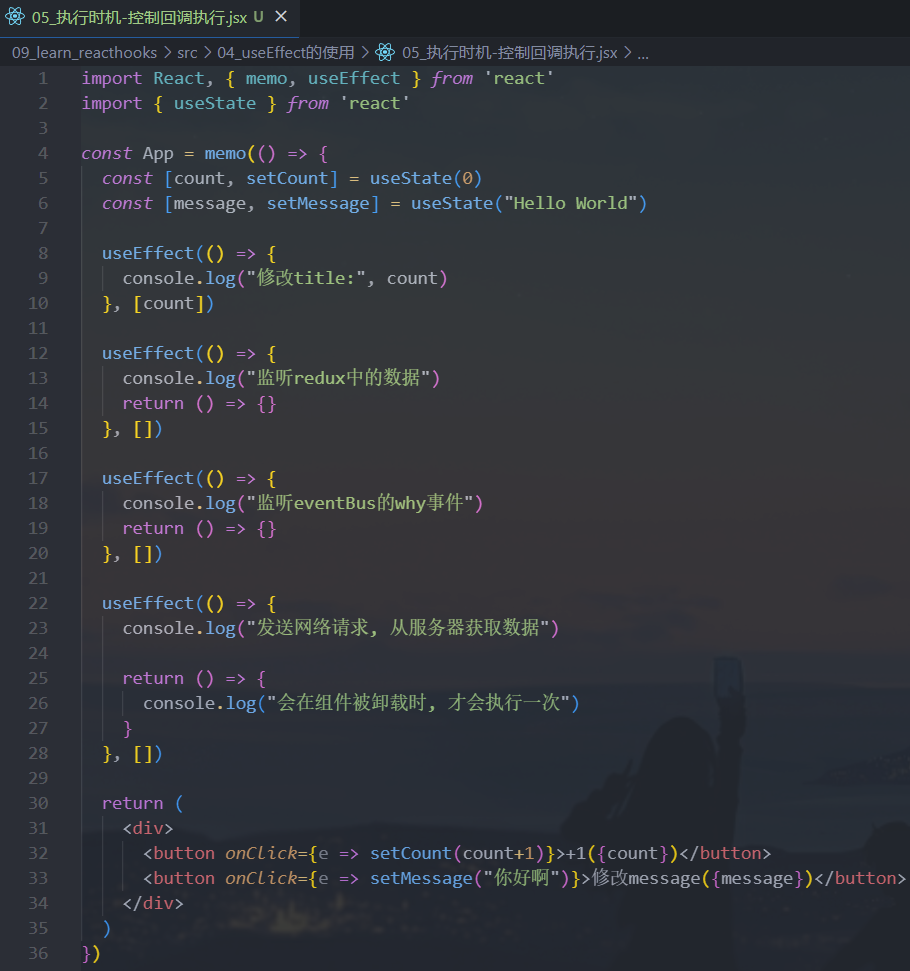
但是,如果一个函数我们不希望依赖任何的内容时,也可以传入一个空的数组
[]:- 那么这里的两个回调函数分别对应的就是
componentDidMount和componentWillUnmount生命周期函数了
- 那么这里的两个回调函数分别对应的就是
三. Context/Reducer
1.useContext的使用
在之前的开发中,我们要在组件中使用共享的
Context有两种方式:- 类组件可以通过
类名.contextType = MyContext方式,在类中获取context - 多个
Context或者在函数式组件中通过MyContext.Consumer方式共享context
- 类组件可以通过
但是多个
Context共享时的方式会存在大量的嵌套:Context Hook允许我们通过Hook来直接获取某个Context的值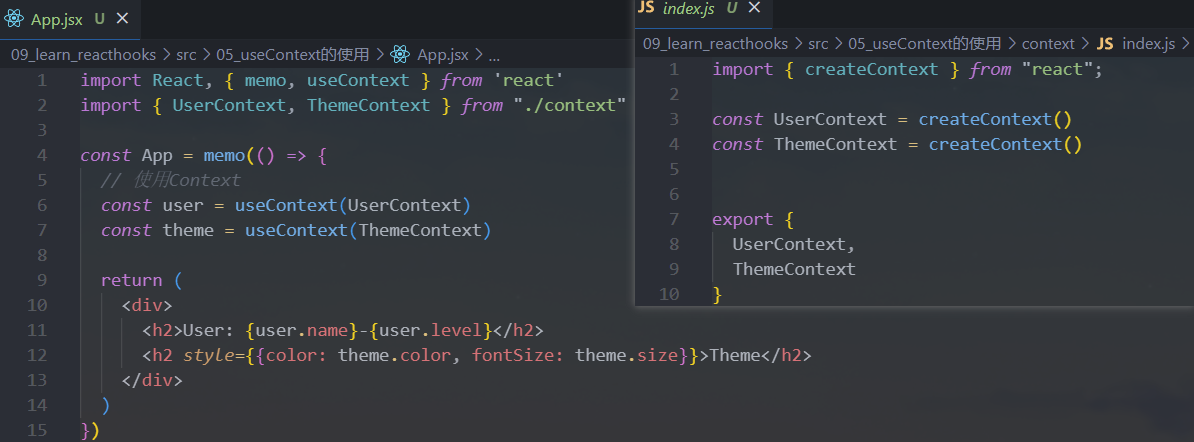
注意事项:
- 当组件上层最近的
<MyContext.Provider>更新时,该Hook会触发重新渲染,并使用最新传递给MyContext provider的context value值
- 当组件上层最近的
2.useReducer
很多人看到
useReducer的第一反应应该是redux的某个替代品,其实并不是useReducer仅仅是useState的一种替代方案:- 在某些场景下,如果
state的处理逻辑比较复杂,我们可以通过useReducer来对其进行拆分 - 或者这次修改的
state需要依赖之前的state时,也可以使用
- 在某些场景下,如果
数据是不会共享的,它们只是使用了相同的
counterReducer的函数而已所以,
useReducer只是useState的一种替代品,并不能替代Redux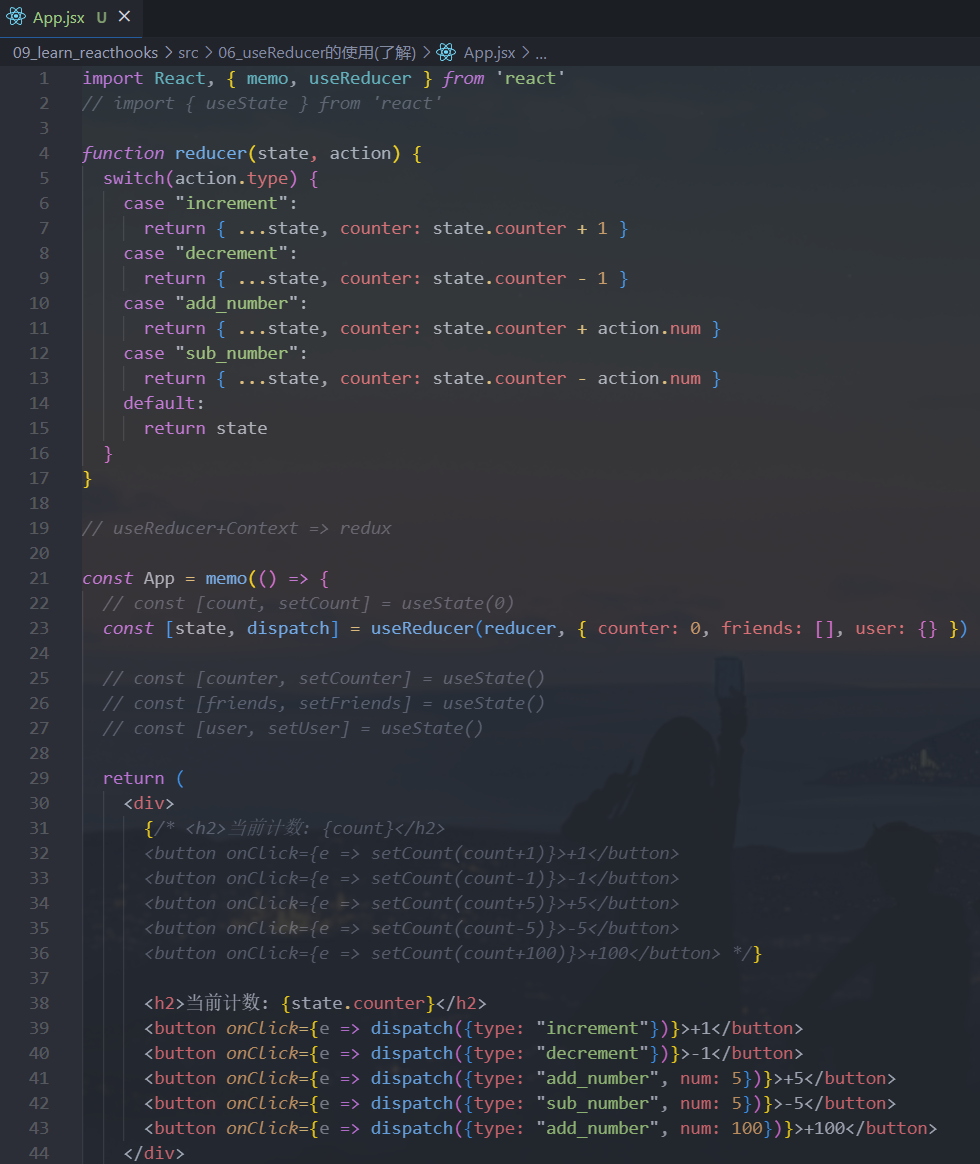
四. Callback/Memo
1.useCallback
useCallback实际的目的是为了进行性能的优化如何进行性能的优化呢?
typescriptconst memoizedCallback = useCallback( () => { doSomething(a, b); }, [a, b], );- 参数一:回调函数
- 参数二:数组
useCallback会返回一个memoized(记忆的)回调函数- 在
useCallback第二个参数中传入的依赖不变的情况下,多次定义传入的第一个参数的时候,返回的值是相同的- 比较是否是同一个值,
react内部采用的Object.is()方法 - 返回的值是相同,即:多次定义传入的回调函数时,
useCallback返回的都是第一次变动时的值(第一次传入的回调函数)
- 比较是否是同一个值,
通常使用
useCallback的目的是不希望子组件进行多次渲染,从而优化性能,并不是为了函数进行缓存useCallback传入的函数,每次在执行的时候,内存表现上还是有创建一个新函数
案例一:使用
useCallback和不使用useCallback定义一个函数是否会带来性能的优化- 不会
案例二:使用
useCallback和不使用useCallback定义一个函数传递给子组件是否会带来性能的优化- 会
注意:
- 默认情况下,父组件传入给子组件的普通函数,在父组件每次状态更新时,会触发父组件重新执行,意味中父组件中的函数也会重新定义,也就意味中每次重新执行父组件时,传入给子组件的普通函数都是一个新的对象,也就会导致子组件的
props改变,从而子组件也会发生不必要的重新执行 - 所以使用
useCallback可以避免这类问题,只有当useCallback传入的依赖变动时,才会导致useCallback的返回值改变,从而子组件才会重新执行
- 默认情况下,父组件传入给子组件的普通函数,在父组件每次状态更新时,会触发父组件重新执行,意味中父组件中的函数也会重新定义,也就意味中每次重新执行父组件时,传入给子组件的普通函数都是一个新的对象,也就会导致子组件的
但是很多时候,一个页面可能里面有引用
n多个子组件,如果一个依赖改变,引发对应的子组件都重新渲染,有时候,我们不想都重新渲染- 可以使用
useRef,在组件多次重新渲染时,返回的都是同一个值,也就意味着我们可以在useRef返回的值身上添加对应的属性,来指向useState返回的状态,从而可以使用添加的属性,来代替useCallback中使用的useStata返回的状态,从而也就不需要给useCallback添加对应的依赖
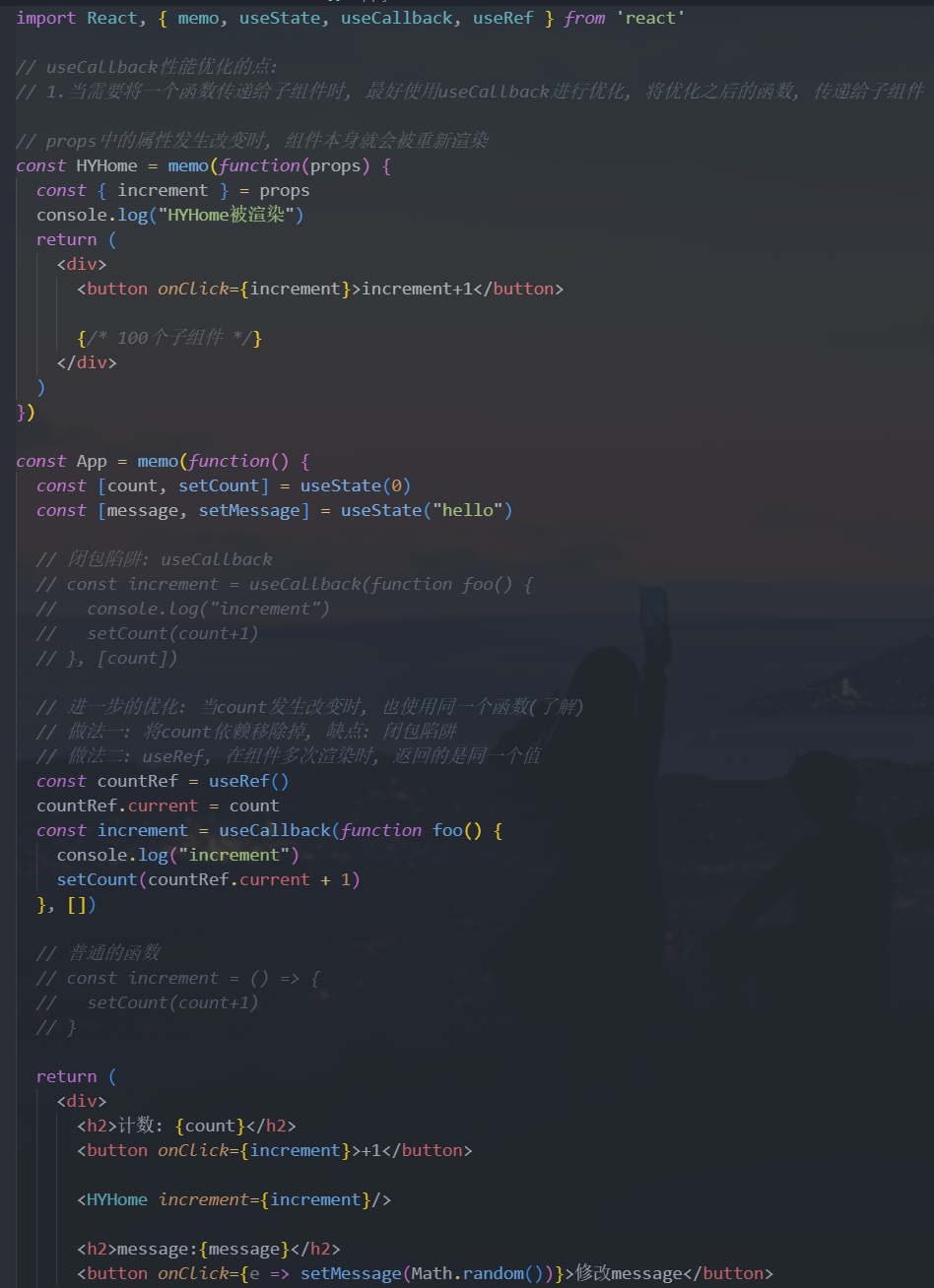
- 可以使用
2.useMemo
useMemo实际的目的也是为了进行性能的优化如何进行性能的优化呢?
useMemo返回的也是一个memoized(记忆的)值- 在依赖不变的情况下,多次定义的时候,返回的值是相同的
typescriptconst memoizedValue = useMemo(() => computeExpensiveValue(a, b), [a, b]);案例一:进行大量的计算操作,是否有必须要每次渲染时都重新计算
案例二:对子组件传递相同内容的对象时,使用
useMemo进行性能的优化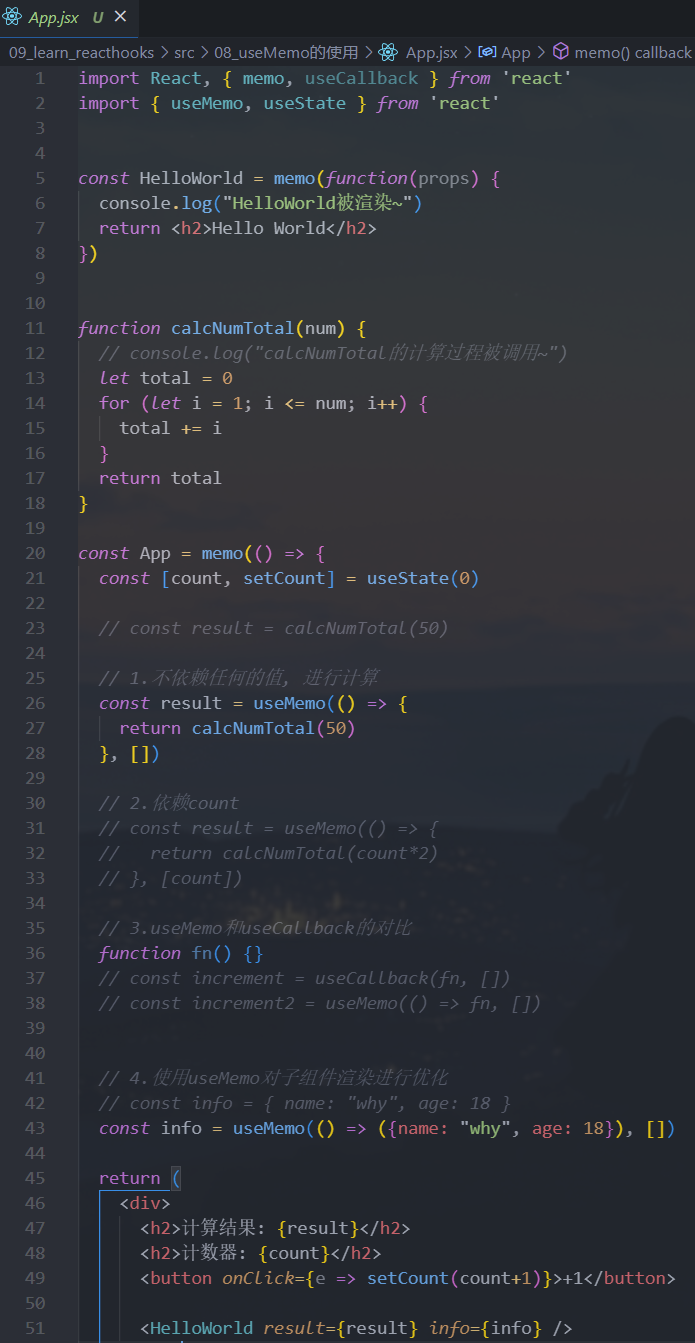
五. Ref/ImperativeHandle/LayoutEffect
1.useRef
useRef返回一个ref对象,其.current属性被初始化为传入的参数,返回的ref对象在组件的整个生命周期保持不变如果你将
ref对象以<div ref={myRef} />形式传入组件,则无论该节点如何改变,React都会将ref对象的.current属性设置为相应的DOM节点最常用的
ref是两种用法:- 用法一:绑定
DOM(或者组件,但是需要是class组件)元素 - 用法二:保存一个数据,这个对象在组件的整个生命周期中可以保存不变
typescriptconst refContainer = useRef(initialValue)- 用法一:绑定
案例一:
useRef绑定DOM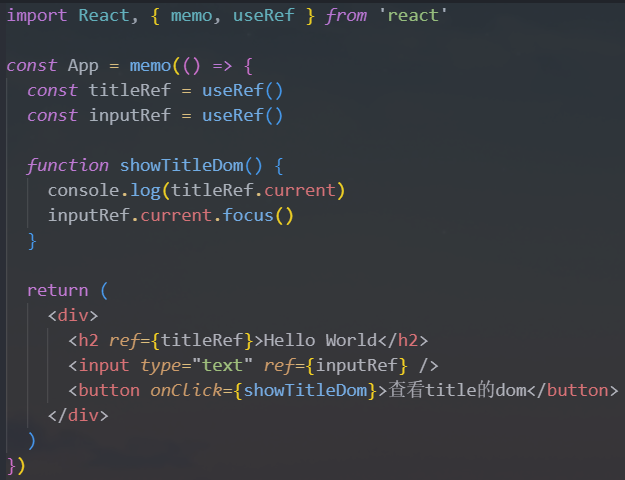
案例二:使用
ref保存上一次的某一个值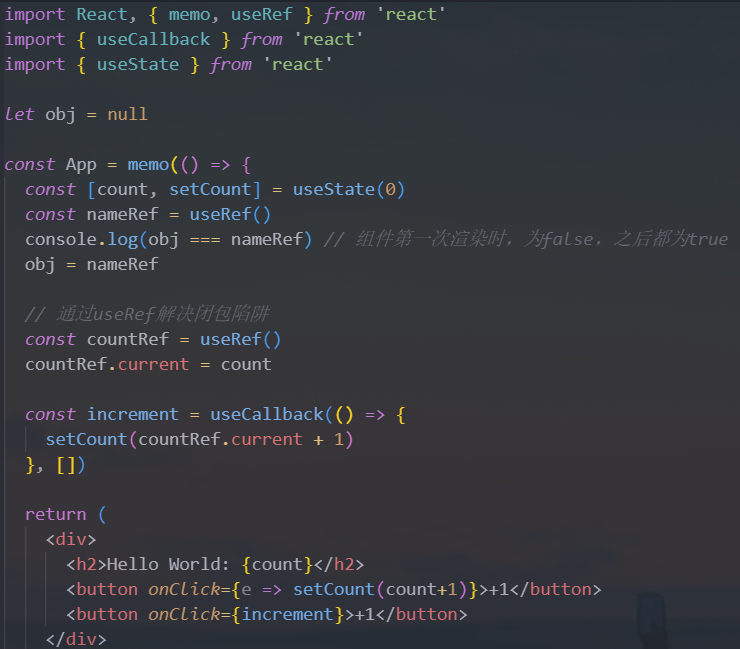
2.useImperativeHandle
useImperativeHandle并不是特别好理解,我们一点点来学习我们先来回顾一下
ref和forwardRef结合使用:- 通过
forwardRef可以将ref转发到函数式子组件 - 子组件拿到父组件中创建的
ref,绑定到自己的某一个元素中
- 通过
forwardRef的做法本身没有什么问题,但是我们是将子组件的DOM直接暴露给了父组件:- 直接暴露给父组件带来的问题是某些情况的不可控
- 父组件可以拿到
DOM后进行任意的操作 - 但是,事实上在上面的案例中,我们只是希望父组件可以操作的
focus,其他并不希望它随意操作
通过
useImperativeHandle可以暴露指定的操作:通过
useImperativeHandle的Hook,将传入的ref和useImperativeHandle第二个参数返回的对象绑定到了一起所以在父组件中,使用
inputRef.current时,实际上使用的是返回的对象比如我调用了
focus函数,甚至可以调用setValue函数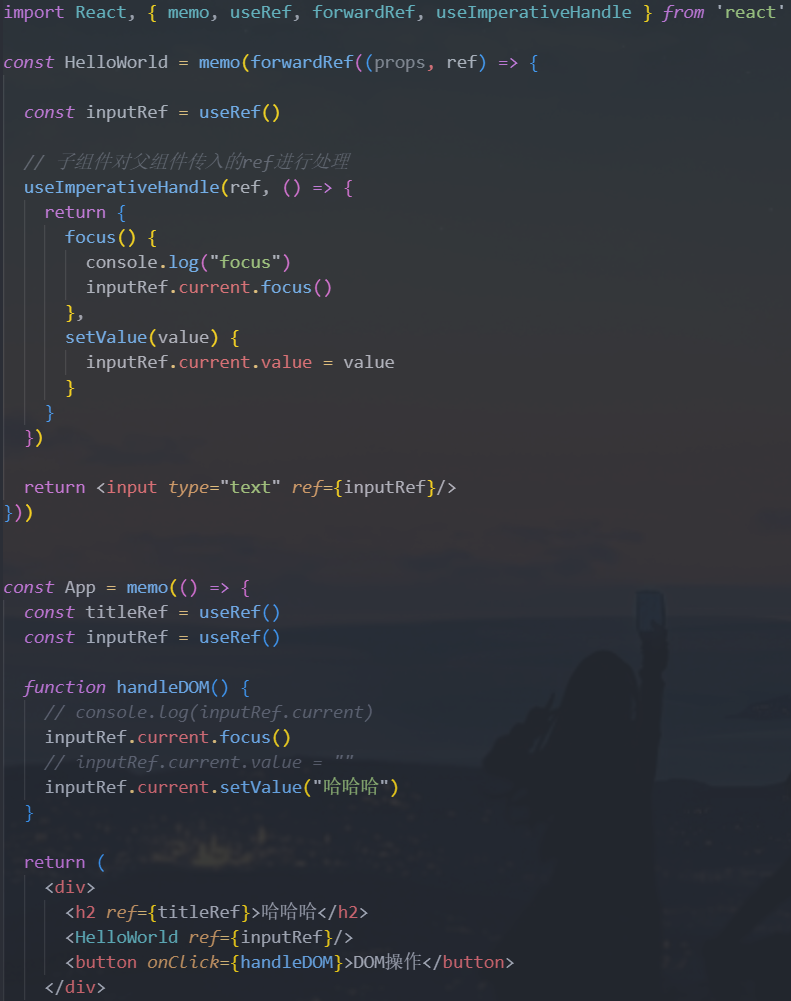
3.useLayoutEffect
useLayoutEffect看起来和useEffect非常的相似,事实上他们也只有一点区别而已:useEffect会在组件渲染的内容更新到DOM上之后执行,不会阻塞DOM的更新useLayoutEffect会在组件渲染的内容更新到DOM上之前执行,会阻塞DOM的更新
如果我们希望在某些操作发生之后再更新
DOM,那么应该将这个操作放到useLayoutEffectuseEffect和useLayoutEffect的对比
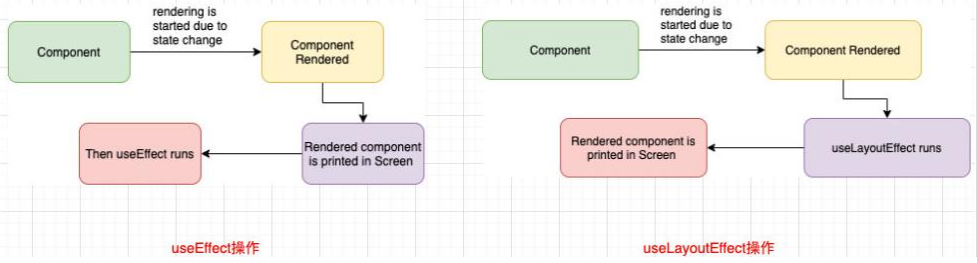
官方更推荐使用
useEffect而不是useLayoutEffect可以在组件渲染完成,尚未更新到
dom上时,可以先进行一个拦截操作或其他的处理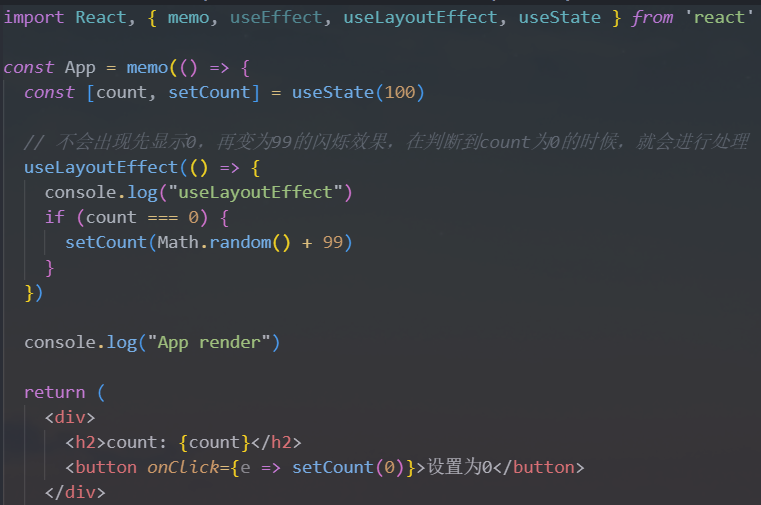
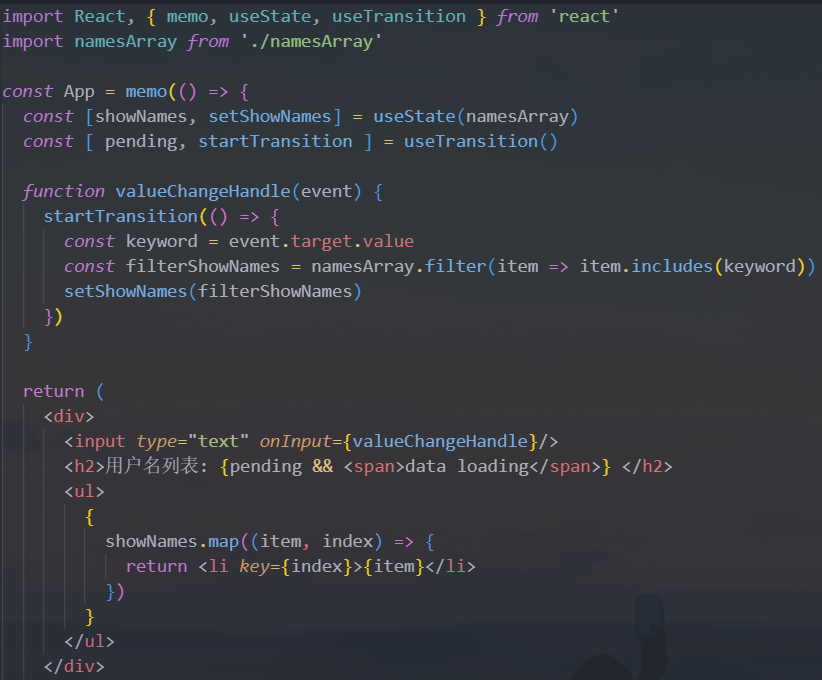
六. Transition/DeffedValue
1.useTransition
官方解释:返回一个状态值表示过渡任务的等待状态,以及一个启动该过渡任务的函数
- 事实上官方的说法,还是让人云里雾里,不知所云
useTransition到底是干嘛的呢?它其实在告诉react对于某部分任务的更新优先级较低,可以稍后进行更新jsconst [isPending, startTransition] = useTransition();返回值是一个数组,数组中有两个元素
- 元素一:布尔值
- 根据元素二中的函数是否执行完来决定是否完成
- 元素二:函数
- 函数中传入一个回调函数,优先级比较低的更新操作可以放入该回调函数
- 元素一:布尔值
注意:
- 过渡任务中触发的更新会让优先级更高的更新先进行,比如点击
- 过渡任务中的更新将不会展示由于再次挂起而导致降级的内容。这个机制允许用户在
React渲染更新的时候继续与当前内容进行交互
案例:
- 当用户在搜索框输入的时候,如果一块执行更新操作,输入框中用户的输入值的更新操作会和数据过滤的更新操作同步执行完之后,才会一起渲染
- 如果数据过滤操作的数据量过大,需要消耗的时间就会比较长,会阻塞输入框中用户的操作更新
- 所以可以使用
useTransition来对数据过滤的更新操作来进行降级,就不会阻塞输入框中用户的操作更新,从而优化用户体验
当然,这种细微的性能优化,我们肉眼比较难感知出来,可以在控制台的
Performance选项,设置CPU未4x slowdow,即性能放慢四倍,通过这种手段,方便我们进行测试
2.useDeferredValue
官方解释:
useDeferredValue接受一个值,并返回该值的新副本,该副本将推迟到更紧急地更新之后在明白了
useTransition之后,我们就会发现useDeferredValue的作用是一样的效果,可以让我们的更新延迟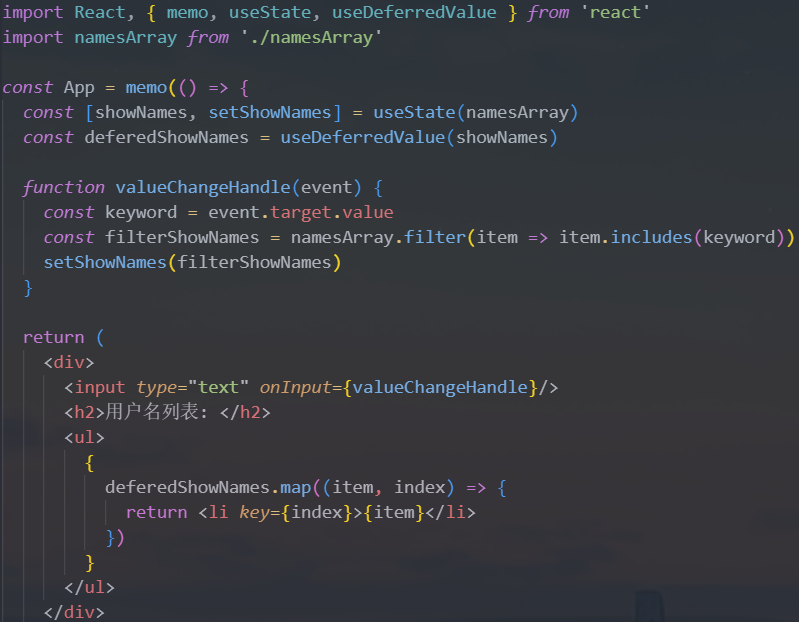
六. 自定义Hooks使用
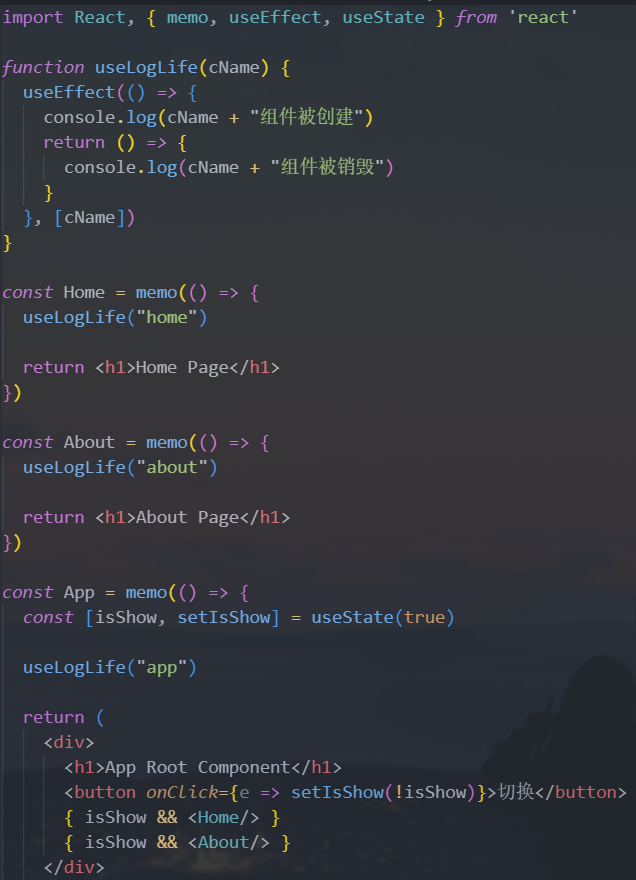
1.自定义Hook
自定义
Hook本质上只是一种函数代码逻辑的抽取,严格意义上来说,它本身并不算React的特性命名要求:须以
use开头进行命名需求:所有的组件在创建和销毁时都进行打印
组件被创建:打印 组件被创建了
组件被销毁:打印 组件被销毁了
2.自定义Hook练习
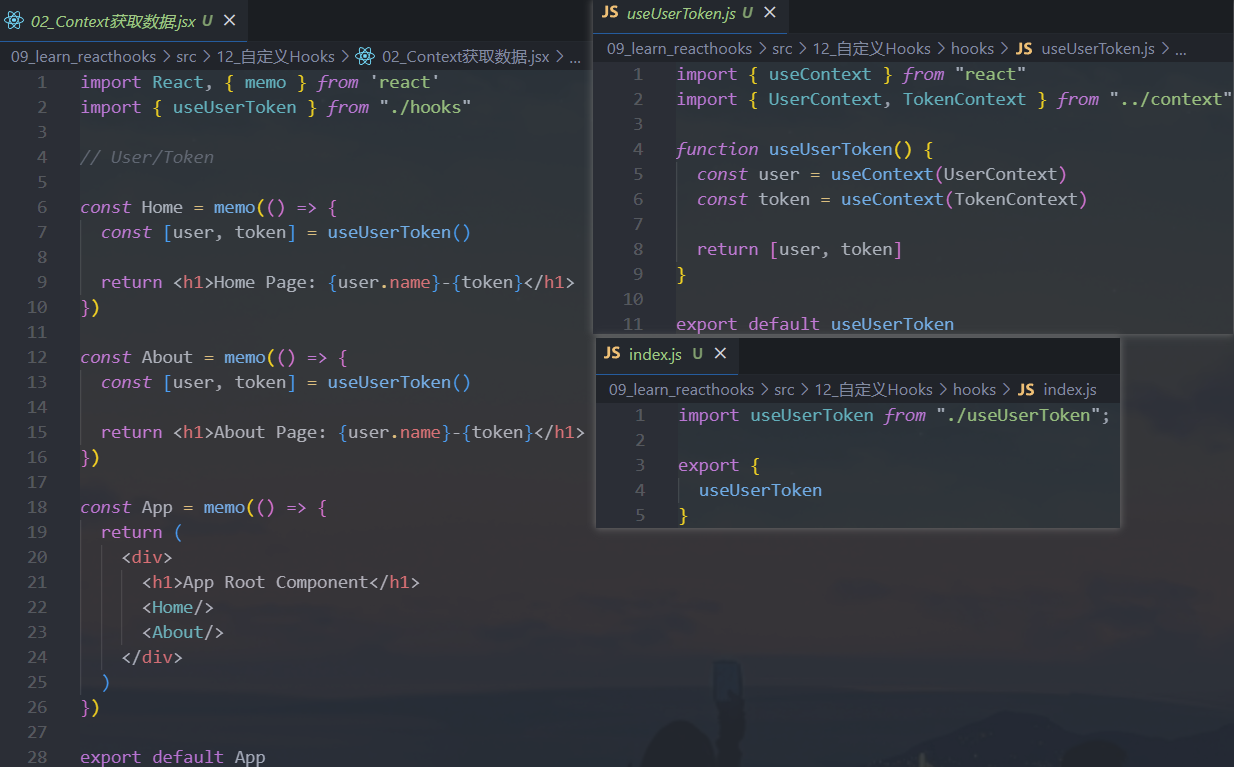
需求一:
Context的共享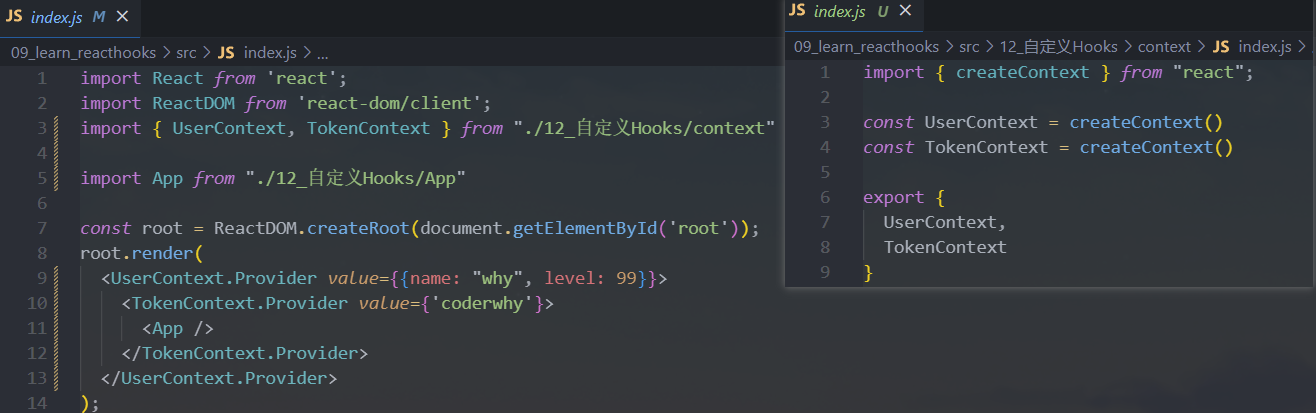
需求二:获取滚动位置
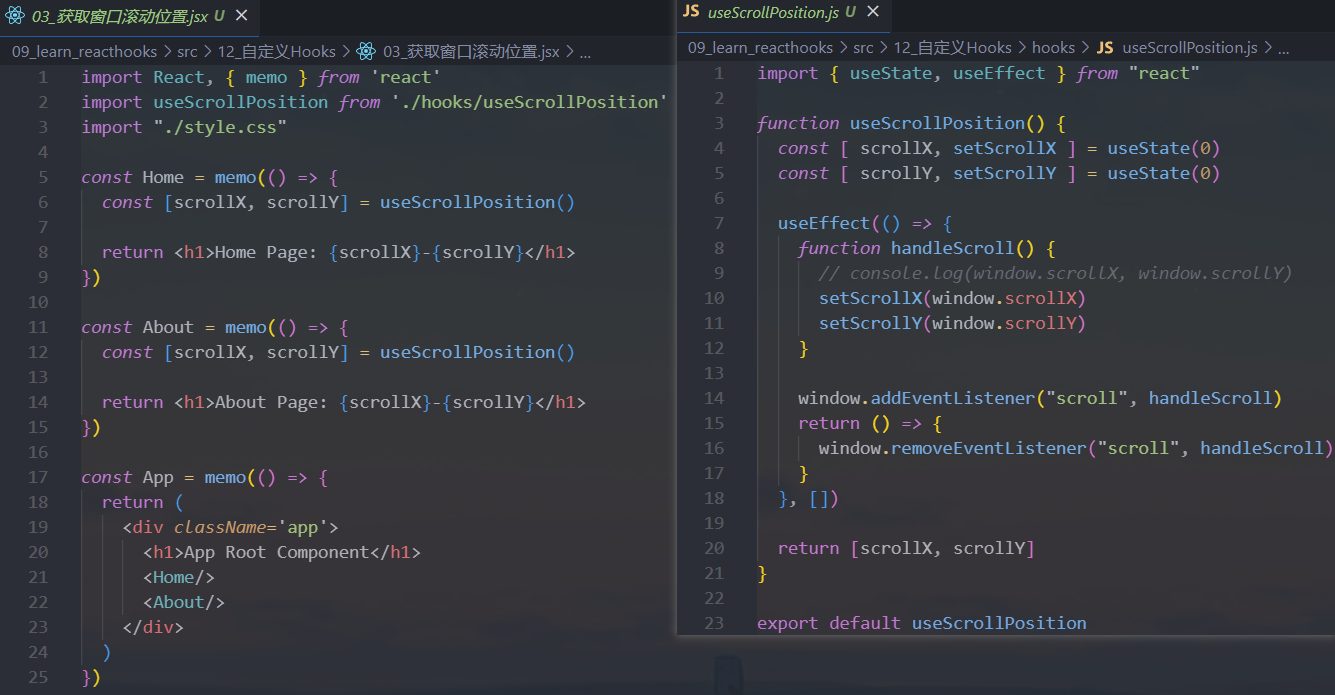
需求三:
localStorage数据存储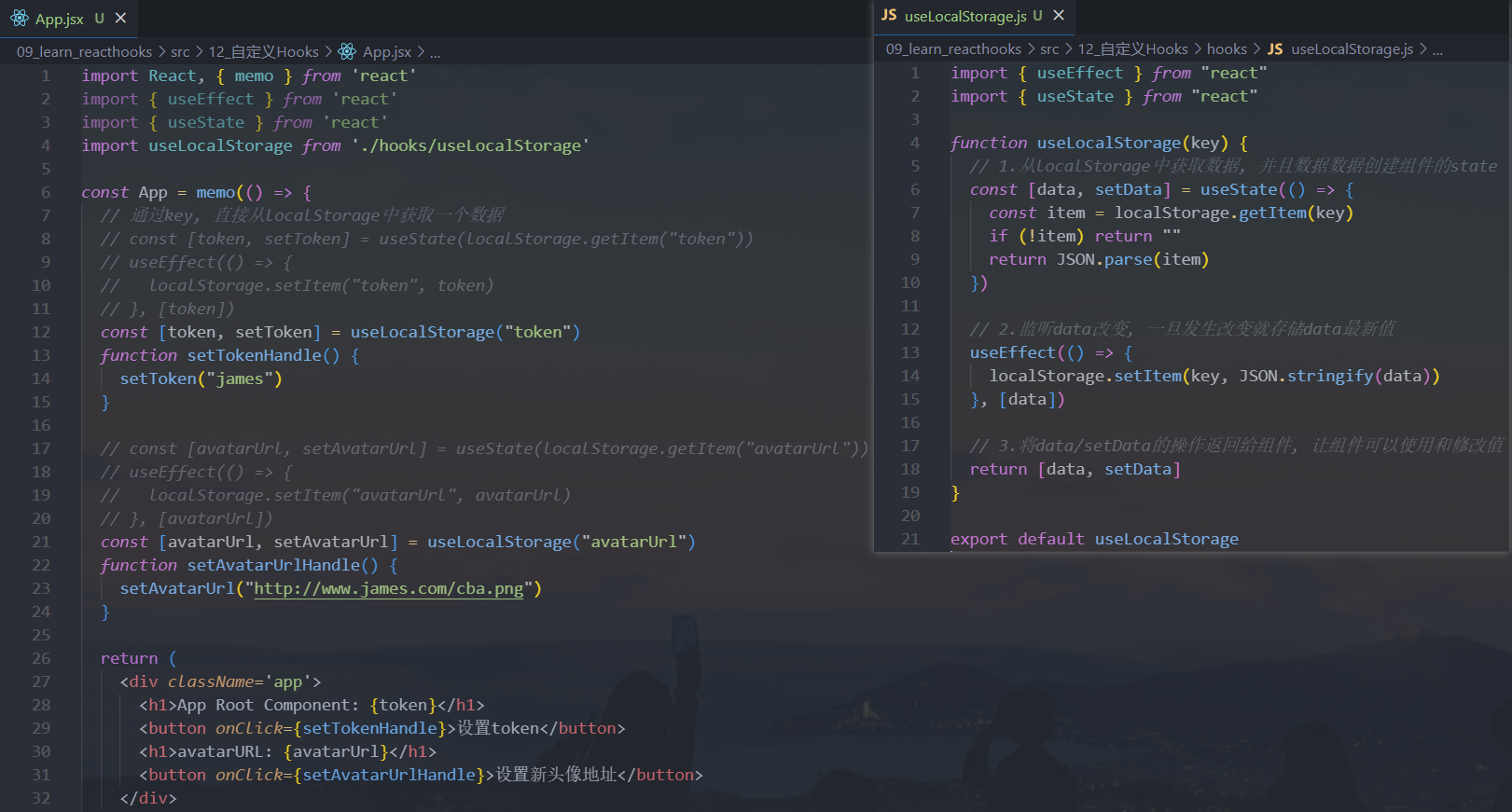
七. redux hooks
在之前的
redux开发中,为了让组件和redux结合起来,我们使用了react-redux中的connect:- 但是这种方式必须使用高阶函数结合返回的高阶组件
- 并且必须编写:
mapStateToProps和mapDispatchToProps映射的函数
在
Redux7.1开始,提供了Hook的方式,我们在函数式组件中再也不需要编写connect以及对应的映射函数了useSelector的作用是将state映射到组件中:- 参数一:将
state映射到需要的数据中- 该参数是一个函数,内部会自动执行该函数,该函数会被传入一个参数
state,该函数返回值是一个对象,在对象中可以映射我们需要的state,该对象最终会作为**useSelector函数的返回值**
- 该参数是一个函数,内部会自动执行该函数,该函数会被传入一个参数
- 参数二:可以进行比较来决定是否组件重新渲染
useSelector默认监听的是整个state对象,只要state发生改变的时候,就会引发使用useSelector组件的重新渲染- 所以我们可以传入第二个参数,
react内置函数shallowEqual,会自动浅层比较当前返回的对象的属性所对应的state中的值与之前返回的对象的属性所对应的state中的值 是否是相等 - 只有改动,才会引发对应的组件重新渲染
- 参数一:将
useSelector默认会比较我们返回的两个对象是否相等- 如何比较呢?
const refEquality = (a, b) => a === b - 也就是我们必须返回两个完全相等的对象才可以不引起重新渲染
- 如何比较呢?
useDispatch使用非常简单,直接获取dispatch函数,之后在组件中直接使用即可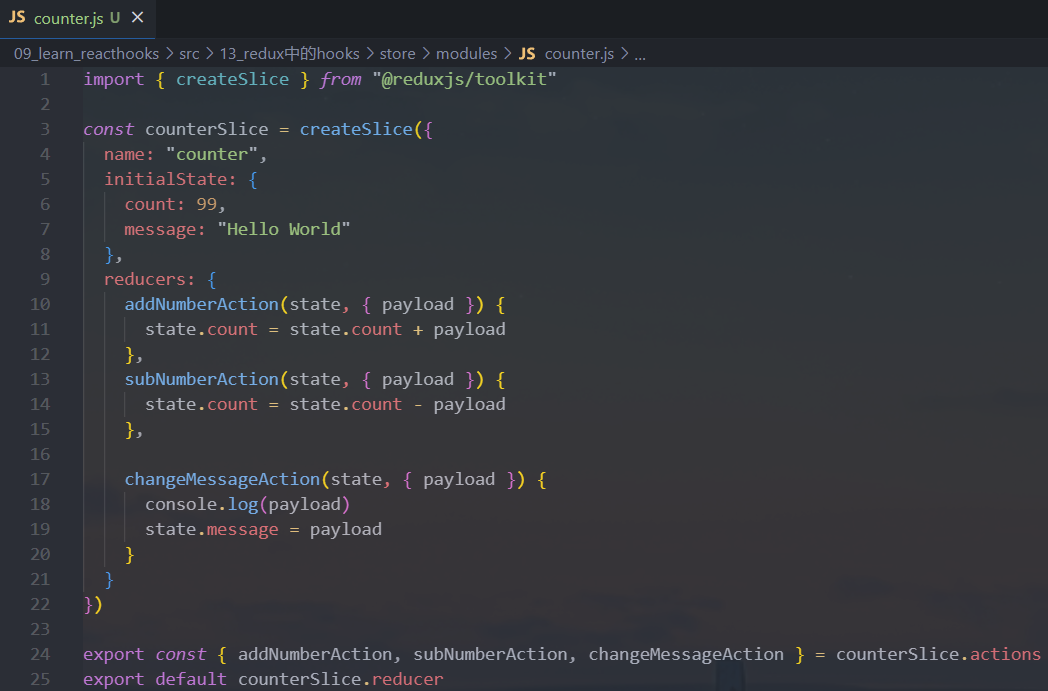
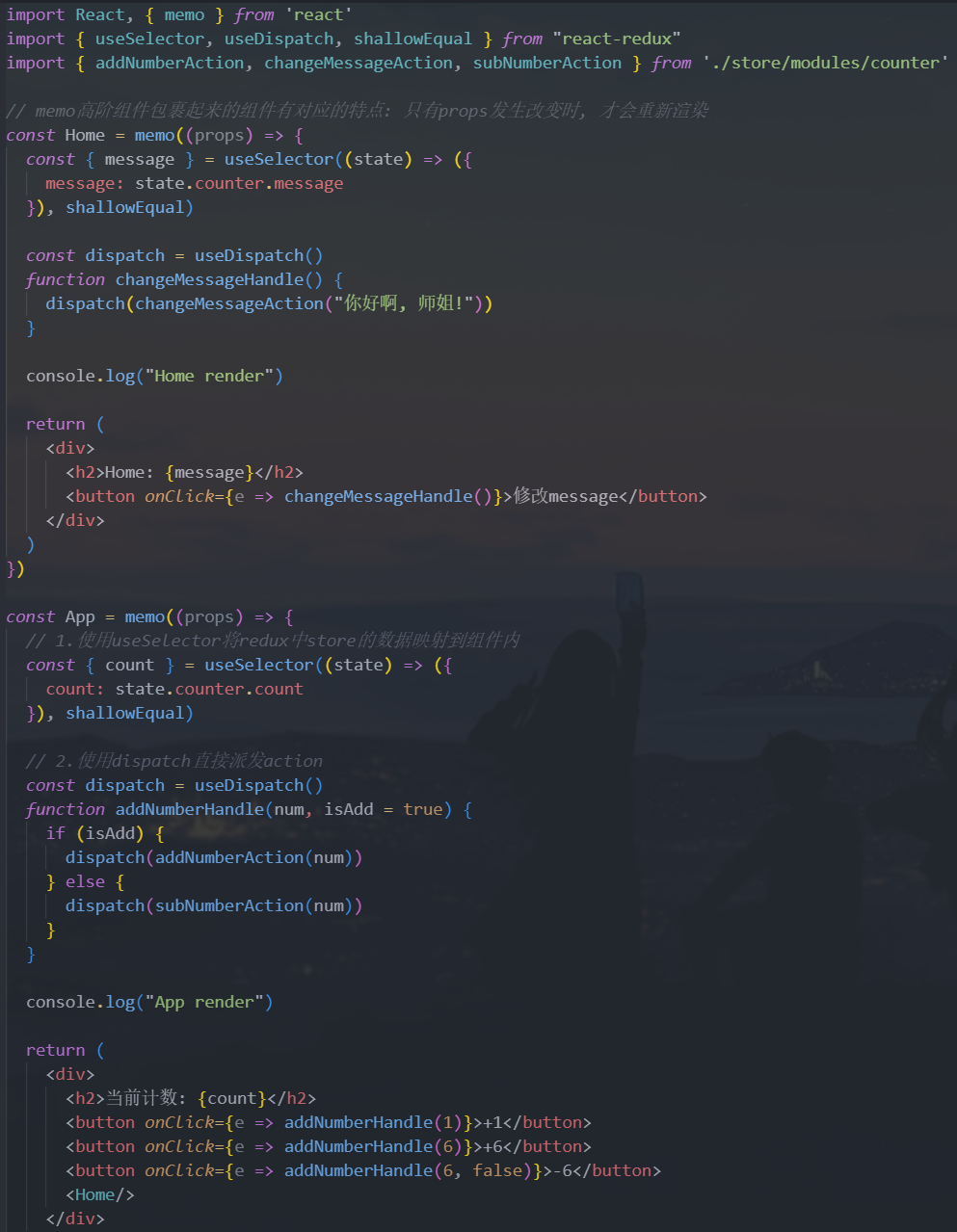
我们还可以通过
useStore来获取当前的store对象,一般使用派发action操作store,一般不推荐直接获取store
8.SSR
1. SPA页面的缺陷和SSR的优势
什么是
SSR?SSR(Server Side Rendering,服务端渲染),指的是页面在服务器端已经生成了完整的HTML页面结构,不需要通过浏览器执行js代码来创建页面结构- 搜索引擎
(SEO)优化- 像类型百度的搜索引擎,有很多台服务器在24小时不间断的爬取网络上的数据,但是一般爬取的主要是
html文件,但是像SPA这样的页面,从服务器刚下载下来的时候,只有一个index.html文件,从而对我们网站进行收录,收录的只有index.html,里面往往都是没有什么数据,并不会对一些引入的js文件的内容也进行爬取,所以在其数据库中收录的相关的关键字,只有index.html中的一些关键字,所以当用户使用百度引擎进行关键字搜索时,网站排序跟收录的关键字数量有关,我们的排名可能就很靠后甚至都没有,所以用户就很可能不会进入我们的网站,也就不会带来相关的流量以及产品的销量等一系列影响,所以说SPA页面非常不利于SEO优化 - 谷歌引擎会执行网站的
js代码,对其内容进行收录的
- 像类型百度的搜索引擎,有很多台服务器在24小时不间断的爬取网络上的数据,但是一般爬取的主要是
- 首屏的渲染速度
SSR页面下载下来的就是一整个完整的网页,浏览器不需要再去下载引入的js代码,执行js代码之后再创建页面结构等等,浏览器直接渲染即可- 而
SPA页面下载下来的首先是一个index.html的文件,之后再根据引入的js文件,去服务器中下载下来对应的文件,而没有做分包处理的js文件(像bundle.js),就很有可能比较大,从而下载下来的时间就越长,下载完之后浏览器还需要执行js文件中的代码,从而阻塞浏览器渲染,从而相对SSR页面,首屏渲染速度就会慢一些
- 搜索引擎
- 对应的是
CSR(Client Side Rendering,客户端渲染),我们开发的SPA页面通常依赖的就是客户端渲染- 浏览器解析:
- 根据域名去服务器请求对应的文件
- 先请求一个文件:
index.html,再去下载引入的js文件等等,然后浏览器运行js代码,创建页面结构,然后浏览器进行渲染 - 基于
hash的历史记录,根本不会被SEO引擎处理,而history在SEO上表现更好
- 先请求一个文件:
- 根据域名去服务器请求对应的文件
- 浏览器解析:
早期的服务端渲染包括
PHP、JSP、ASP等方式,但是在目前前后端分离的开发模式下,前端开发人员不太可能再去学习PHP、JSP等技术来开发网页不过我们可以借助于
Node来帮助我们执行js代码,提前完成页面的结构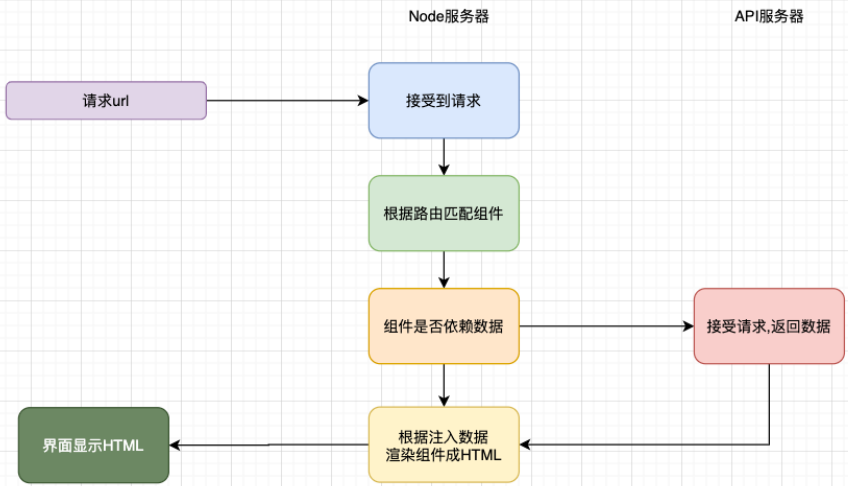
2.SSR同构应用
什么是同构?
- 一套代码既可以在服务端运行又可以在客户端运行,这就是同构应用
同构是一种
SSR的形态,是现代SSR的一种表现形式当用户发出请求时,先在服务器通过
SSR渲染出首页的内容但是对应的代码同样可以在客户端被执行
执行的目的包括事件绑定等以及其他页面切换时也可以在客户端被渲染
- 因为
Node里创建出来的html结构,只是一串字符串,意味着并没有绑定js的事件 - 所以
Node中输出的这套html结构,最终目的只是为了先让用户看到页面展示 - 页面的交互操作,之后在浏览器中运行对应的代码,从而绑定交互事件,这个过程也就是注入(
hydrate)
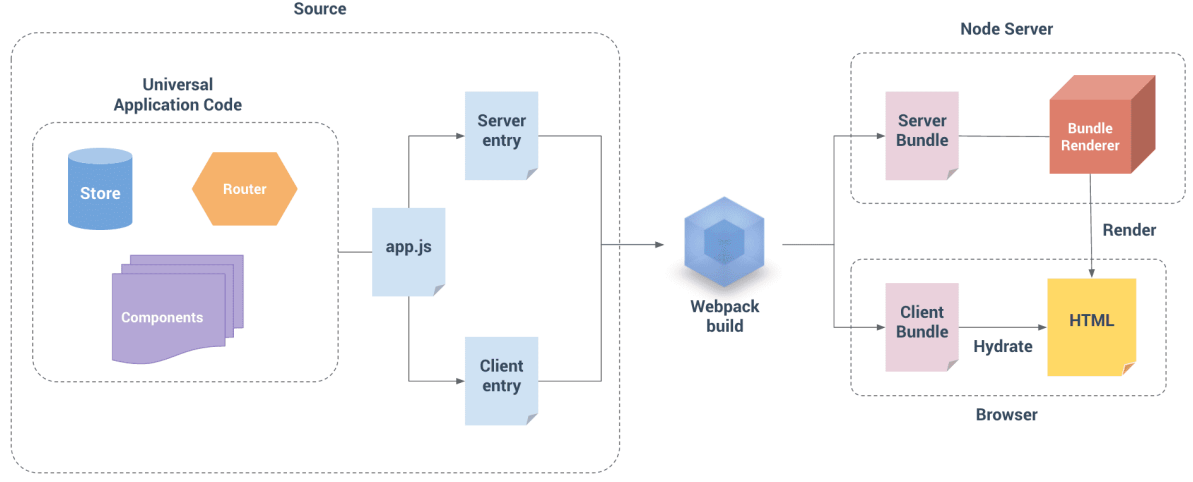
- 因为
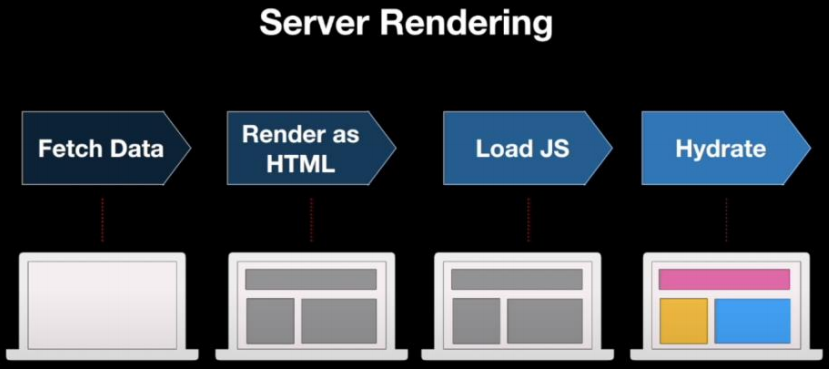
3.Hydration
什么是
Hydration?这里引入vite-plugin-ssr插件的官方解释<img image-20220921184610862.png" alt="image-20220921184610862" style="zoom:80%;" />
在进行
SSR时,我们的页面会呈现为HTML- 但仅
HTML不足以使页面具有交互性。例如,浏览器端没有js的页面不能是交互式的(没有js事件处理程序来响应用户操作,如单击按钮) - 为了使我们的页面具有交互性,除了在
Node.js中将页面呈现为HTML之外,我们的UI框架(Vue/React/...)还在浏览器中加载和呈现页面(它创建页面的内部表示,然后将内部表示映射到我们在Node.js中呈现的HTML的DOM元素)
- 但仅
这个过程称为
hydration
4.useId
react18新增hook官方的解释:
useId是一个用于生成横跨服务端和客户端的稳定的唯一ID的,同时避免hydration过程中id不匹配的情况`- 底层根据组件树的结构来生成的,因为是同一套代码,所以服务端和客户端都是一样的组件树结构
在服务端和客户端中,不管组件重新渲染多少次,生成的
useId永远是唯一的所以我们可以得出如下结论:
useId是用于react的同构应用开发的,前端的SPA页面并不需要使用它useId可以保证应用程序在客户端和服务器端生成唯一的ID这样可以有效的避免通过一些手段/算法在服务端和客户端生成的
id不一致,在后续使用过程中,就会造成hydration mismatch不匹配如果
id不一样,需要重新渲染对应的dom,一样的话,可以在某种程度上做性能优化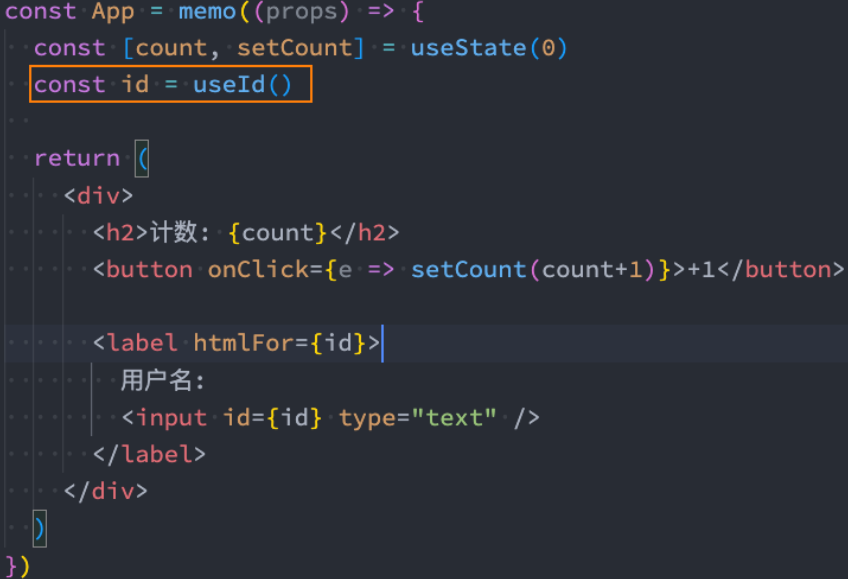
由于
for在js中是保留字,所以React元素中使用了htmlFor来代替