一.Storage
1. Storage
Web Storage API主要提供了一种机制,可以让浏览器提供一种比cookie更直观的方式存储key-value对主要包含如下两种机制:
localStorage:本地存储,提供的是一种永久性的存储方法,在关闭掉网页重新打开时,存储的内容依然保留sessionStorage:会话存储,提供的是本次会话的存储,在关闭掉会话时,存储的内容会被清除- 页面会话在浏览器打开期间一直保持,并且重新加载或恢复页面仍会保持原来的页面会话
- 打开多个相同的
URL的Tabs页面,会创建各自的sessionStorage - 关闭对应浏览器标签或窗口,会清除对应的
sessionStorage
注意:不管是
sessionStorage还是localStorage,二者都是特定于同源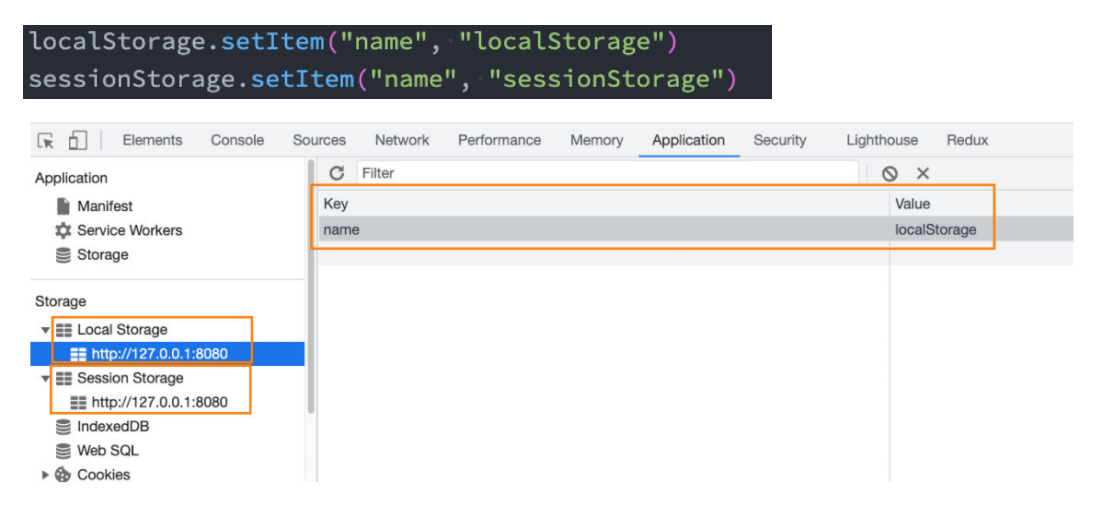
2. localStorage 和 SessionStorage 的区别
- 我们会发现
localStorage和sessionStorage看起来非常的相似 - 那么它们有什么区别呢?
- 验证一:关闭网页后重新打开,
localStorage会保留,而sessionStorage会被删除 - 验证二:在当前页面内实现同源跳转,
localStorage会保留,sessionStorage也会保留 - 验证三:在当前页面打开一个同源下的新网页,新网页中
localStorage会保留,sessionStorage不会被保留
- 验证一:关闭网页后重新打开,
3. Storage 常见的属性和方法
Storage有如下的属性和方法:- 属性:
Storage.length:只读属性- 返回一个整数,表示存储在
Storage对象中的数据项数量
- 返回一个整数,表示存储在
- 方法:
Storage.key():该方法接受一个数值n作为参数,返回存储中的第n个key名称Storage.getItem():该方法接受一个key作为参数,并且返回key对应的valueStorage.setItem():该方法接受一个key和value,并且将会把key和value添加到存储中- 如果
key已有值存储,则更新其对应的值
- 如果
Storage.removeItem():该方法接受一个key作为参数,并把该key从存储中删除Storage.clear():该方法的作用是清空存储中的所有key
4. Storage 工具封装
<script src="./js/cache.js"></script> // 这里引入封装的js工具文件
<script>
localCache.setCache("sno", 111)
// storage本身是不能直接存储对象类型的
const userInfo = {
name: "why",
nickname: "coderwhy",
level: 100,
imgURL: "http://github.com/coderwhy.png"
}
// localStorage.setItem("userInfo", JSON.stringify(userInfo))
// console.log(JSON.parse(localStorage.getItem("userInfo")))
sessionCache.setCache("userInfo", userInfo)
console.log(sessionCache.getCache("userInfo"))
</script>// 封装的js工具文件
class Cache {
constructor(isLocal = true) {
this.storage = isLocal ? localStorage: sessionStorage
}
setCache(key, value) {
if (!value) {
throw new Error("value error: value必须有值!")
}
// 这里可以再做些边界值判断,比如函数、undefined这些
// 因为undefined、任意的函数以及symbol值,在序列化过程中会被忽略(出现在非数组对象的属性值中时)或者被转换成null(出现在数组中时)。函数、undefined被单独转换时,会返回undefined,如JSON.stringify(function(){}) 或JSON.stringify(undefined)
if (value) {
this.storage.setItem(key, JSON.stringify(value))
}
}
getCache(key) {
const result = this.storage.getItem(key)
if (result) {
return JSON.parse(result)
}
}
removeCache(key) {
this.storage.removeItem(key)
}
clear() {
this.storage.clear()
}
}
const localCache = new Cache()
const sessionCache = new Cache(false)二. 正则表达式的使用
1. 什么是正则表达式?
我们先来看一下维基百科对正则表达式的解释:
正则表达式(英语:
Regular Expression,常简写为regex、regexp或RE),又称正则表示式、正则表示法、规则表达式、常规表示法,是计算机科学的一个概念正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串
许多程序设计语言都支持利用正则表达式进行字符串操作
简单概况:正则表达式是一种字符串匹配利器,可以帮助我们搜索、获取、替代字符串
MDN解释:正则表达式是用于匹配字符串中字符组合的模式,js中正则表达式也是个对象在
js中,正则表达式使用RegExp类(构造函数)来创建,也有对应的字面量的方式:- 正则表达式主要由两部分组成:模式(
patterns)和修饰符(flags)
js// 创建正则 // 1> 匹配的规则 pattern // 2> 匹配的修饰符 flags const re1 = new RegExp("abc", "ig") const re2 = /abc/ig- 正则表达式主要由两部分组成:模式(
2. 常用方法
有了正则表达式我们要如何使用它呢?
js中的正则表达式被用于RegExp的exec和test方法- 也包括
String的match、matchAll、replace、search和split方法
RegExp.prototype.exec():在一个指定字符串中执行一个搜索匹配。返回一个结果数组或nulljsconst str = 'hello world' const regExp = /he/i console.log(regExp.exec(str)) // ['he', index: 0, input: 'hello world', groups: undefined]RegExp.prototype.test():执行一个检索,用来查看正则表达式与指定的字符串是否匹配。返回true或falsejsconst str = 'hello world' const regExp = /he/i console.log(regExp.test(str)) // trueString.prototype.match():执行一个检索,返回一个字符串匹配正则表达式的结果- 如果使用
g标志,则将返回与完整正则表达式匹配的所有结果,但不会返回捕获组 - 如果未使用
g标志,则仅返回第一个完整匹配及其相关的捕获组(Array)。 在这种情况下,返回的项目将具有如下所述的其他属性groups:一个命名捕获组对象,其键是捕获组名称,值是捕获组,如果未定义命名捕获组,则为undefinedindex:匹配的结果的开始位置input:搜索的字符串
jsconst str = 'hello world' const regExp = /he/i console.log(str.match(regExp)) // ['he', index: 0, input: 'hello world', groups: undefined]- 如果使用
String.prototype.matchAll():返回一个包含所有匹配正则表达式的结果及分组捕获组的迭代器(不可重用,结果耗尽需要再次调用方法,获取一个新的迭代器)RegExp必须是设置了全局模式g的形式,否则会抛出异常TypeError
jsconst str = 'hello world' const regExp = /he/ig console.log(str.matchAll(regExp)) // RegExpStringIterator {} console.log(str.matchAll(regExp).next()) // {value: Array(1), done: false} console.log(str.matchAll(regExp).next().value) // ['he', index: 0, input: 'hello world', groups: undefined] for (const item of str.matchAll(regExp)) { console.log(item) // ['he', index: 0, input: 'hello world', groups: undefined] }String.prototype.search():执行正则表达式和String对象之间的一个搜索匹配,匹配成功返回索引值,否则返回-1jsconst str = 'hello world' const regExp = /e/ig console.log(str.search(regExp)) // 1String.prototype.replace():返回一个由替换值(replacement)替换部分或所有的模式(pattern)匹配项后的新字符串jsconst str = 'hello world' const regExp = /L/ig console.log(str.replace(regExp, 'X')) // heXXo worXd console.log(str.replace('l', 'X')) // heXlo world console.log(str.replace(regExp, function() { return 'X' })) // heXXo worXdString.prototype.replaceAll():返回一个新字符串,新字符串所有满足pattern的部分都已被replacement替换RegExp必须是设置了全局模式g的形式,否则会抛出异常TypeError
jsconst str = 'hello world' const regExp = /l/ig console.log(str.replaceAll(regExp, 'X')) // heXXo worXdString.prototype.split():使用指定的分隔符字符串将一个String对象分割成子字符串数组,以一个指定的分割字串来决定每个拆分的位置jsconst str = 'hello world' const regExp = /o/ig console.log(str.split(regExp)) // ['hell', ' w', 'rld']
3. 修饰符 flag 的使用
常见的修饰符:
g:检索全部的(global)i:忽略大小写(ignore)m:多行检索(multipe)
案例:
- 获取一个字符串中所有的
abc - 将一个字符串中的所有
abc换成大写
jsconst msg = 'hello ABC, abc, aBC, AABc' console.log(msg.match(/abc/ig)) // ['ABC', 'abc', 'aBC', 'ABc']- 获取一个字符串中所有的
4. 规则 - 字符类(character classes)
字符类是一个特殊的符号,匹配特定集中的任何符号

反向类(
Inverse classes)\D非数字:除\d以外的任何字符,例如字母\S非空格符号:除\s以外的任何字符,例如字母\W非单字字符:除\w以外的任何字符,例如非拉丁字母或空格
jsconst str = 'hello world90' const regExp = /\d/ig console.log(str.match(regExp)) // ['9', '0']
5. 规则 - 锚点(Anchors)
符号
^和符号$在正则表达式中具有特殊的意义,它们被称为“锚点”- 符号
^匹配文本开头 - 符号
$匹配文本末尾
jsconst message = "My name is LATER." // 字符串方法 if (message.startsWith('my')) console.log("以my开头") if (message.endsWith("later")) console.log("以later结尾") // 正则: 锚点 if (/^my/i.test(message)) console.log("正则: 以my开头") // 正则: 以my开头 if (/later\.$/i.test(message)) console.log("正则: 以later.结尾") // 正则: 以later.结尾 console.log(/^coder$/.test("codper")) // false- 符号
词边界(
Word boundary)- 词边界
\b是一种检查,就像^和$一样,它会检查字符串中的位置是否是词边界\b位于字符左侧就是检查字符左侧是否匹配\w,右侧同理
- 词边界测试
\b检查位置的一侧是否匹配\w,而另一侧则不匹配\w
- 词边界
在字符串
Hello, Java!中,以下位置对应于\b: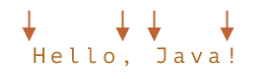 js
js// \w '单字'字符,拉丁字母或数字或下划线_ const message = "My name! is WHY." // 需求: name, name必须是一个单独的词 // 词边界 if (/\bname\b/i.test(message)) { // '!' 不属于 \w 的范畴 console.log("有name, name有边界") // 有name, name有边界 } // 词边界的应用 const infos = "now time is 11:56, 12:00 eat food, number is 123:456" const timeRe = /\b\d\d:\d\d\b/ig infos.match(timeRe) // ['11:56', '12:00'] '1 2'.match(/\b\d\b/g) // ['1', '2'] /\bo/.test('hello') // false 因为o的左侧是匹配\w的
6. 规则 - 转义字符串
如果要把特殊字符作为常规字符来使用,需要对其进行转义:
- 只需要在它前面加个反斜杠
常见的需要转义的字符:
[] \ ^ $ . | ? * + ()- 斜杠符号
/并不是一个特殊符号,但是在字面量正则表达式中也需要转义
- 斜杠符号
练习:匹配所有以
.js或.jsx结尾的文件名jsconst fileNames = ['abc.js', 'cba.java', 'nba.html', 'mba.js', 'cab.jsx'] console.log( fileNames.filter(item => /\.jsx?$/.test(item) )) // ['abc.js', 'mba.js', 'cab.jsx']在
webpack当中,匹配文件名时就是以这样的方式
7. 集合(Sets)和范围(Ranges)
有时候我们只要选择多个匹配字符的其中之一就可以:
- 在方括号
[…]中的几个字符或者字符类意味着 "搜索给定的字符中的任意一个"
- 在方括号
集合
Sets- 比如说,
[eao]意味着查找字符a、e、o中的任意一个,即匹配集合中的单个字符即可
- 比如说,
范围
Ranges- 方括号也可以包含字符范围
- 比如说,
[a-z]会匹配从a到z范围内的字母,[0-5]表示从0到5的数字 [0-9A-F]表示两个范围:它搜索一个字符,满足数字0到9或字母A到F\d—— 和[0-9]相同\w—— 和[a-zA-Z0-9_]相同
案例:匹配手机号码
jsconst phone = ['132', '122', '143', '158', '199'] console.log( phone.filter( item => /^1[3-9]\d/.test(item)) ) // ['132', '143', '158', '199'] const phoneArr = ['13218902345', '12218902345', '14318902345', '19909098989'] console.log( phoneArr.filter(item => /^1[3-9]\d{9}/.test(item)) ) // ['13218902345', '14318902345', '19909098989']排除范围:除了普通的范围匹配,还有类似
[^...]的“排除”范围匹配jsconst phone = ['132', '122', '143', '158', '199'] console.log( phone.filter(item => /^1[^3-9]/.test(item)) ) // ['122']
8. 量词(Quantifiers)
假设我们有一个字符串 +7(903)-123-45-67,并且想要找到它包含的所有数字
- 因为它们的数量是不同的,所以我们需要给与数量一个范围
- 用来形容我们所需要的数量的词被称为量词
数量
{n}- 确切的位数:
{n} - 某个范围的位数:
{n,m}
- 确切的位数:
缩写:
+:代表“一个或多个”,相当于{1,}?:代表“零个或一个”,相当于{0,1}。换句话说,它使得符号变得可选*:代表着“零个或多个”,相当于{0,}。也就是说,这个字符可以多次出现或不出现
案例:匹配开始或结束标签
jsconst message = "fdppp2fdppppppsf42532fdppgjkljlppppf" console.log( message.match(/p+/ig) ) // ['ppp', 'pppppp', 'pp', 'pppp'] const htmlElement = "<div><span>哈哈哈</span><h2>我是标题</h2><p>元素p</p></div>" console.log( htmlElement.match(/<\/?[a-z][a-z0-9]*>/ig) ) // ['<div>', '<span>', '</span>', '<h2>', '</h2>', '<p>', '</p>', '</div>']
9. 贪婪(Greedy)和惰性(lazy)模式
如果我们有这样一个需求:匹配下面字符串中所有使用
《》包裹的内容jsconst message = "我最喜欢的两本书: 《黄金时代》和《沉默的大多数》、《一只特立独行的猪》" // 默认 .+ 采用贪婪模式 console.log( message.match(/《.+》/ig) ) // ['《黄金时代》和《沉默的大多数》、《一只特立独行的猪》']默认情况下的匹配规则是查找到匹配的内容后,会继续向后查找,一直找到最后一个匹配
- 这种匹配的方式,我们称之为贪婪模式(
Greedy)
- 这种匹配的方式,我们称之为贪婪模式(
懒惰模式中的量词与贪婪模式中的是相反
- 只要获取到对应的内容后,就不再继续向后匹配
- 我们可以在量词后面再加一个问号
?来启用懒惰模式 - 所以匹配模式变为
*?或+?,甚至将?变为??
jsconst message = "我最喜欢的两本书: 《黄金时代》和《沉默的大多数》、《一只特立独行的猪》" console.log( message.match(/《.+?》/ig) ) // ['《黄金时代》', '《沉默的大多数》', '《一只特立独行的猪》'
10. 捕获组(capturing group)
模式的一部分可以用括号括起来
(...),这称为“捕获组(capturing group)”这有两个作用:
- 它允许将匹配的一部分作为结果数组中的单独项
- 它将小括号里面的内容视为一个整体
js// 将捕获组作为整体 const info = "dfabcabcfabcdfdabcabcabcljll;jk;j" console.log( info.match(/(abc){2,}/ig) ) // ['abcabc', 'abcabcabc']方法
str.match(regexp),如果regexp没有g标志,将查找第一个匹配并将它作为一个数组返回:- 在索引 0 处:完全匹配
- 在索引 1 处:第一个括号的内容
- 在索引 2 处:第二个括号的内容
- ...依次内推
js// 捕获组 const message = "我最喜欢的两本书: 《黄金时代》和《沉默的大多数》、《一只特立独行的猪》" const iterator = message.matchAll(/(《)(?<why>.+?)(》)/ig) for (const item of iterator) { console.log(item) console.log(`${item[1]}、${item[2]}、 ${item[3]}`) } // ['《黄金时代》', '黄金时代', index: 10, input: '我最喜欢的两本书: 《黄金时代》和《沉默的大多数》、《一只特立独行的猪》', groups: {…}] // 《、黄金时代、 》 // ['《沉默的大多数》', '沉默的大多数', index: 17, input: '我最喜欢的两本书: 《黄金时代》和《沉默的大多数》、《一只特立独行的猪》', groups: {…}] // 《、沉默的大多数、 》 // ['《一只特立独行的猪》', '《', '一只特立独行的猪', '》', index: 26, input: '我最喜欢的两本书: 《黄金时代》和《沉默的大多数》、《一只特立独行的猪》', groups: {…}] // 《、一只特立独行的猪、 》案例:匹配到
HTML标签,并且获取其中的内容jsconst str = '<h1>title</h1>' const result = str.match(/<([a-z0-9]+)>/i) console.log(result[0]) // <h1> console.log(result[1]) // h1
11. 捕获组的补充
命名组:
- 用数字记录组很困难
- 对于更复杂的模式,计算括号很不方便。我们有一个更好的选择:给括号起个名字
- 这是通过在开始括号之后立即放置
?<name>来完成的
jsconst message = "我最喜欢的两本书: 《黄金时代》和《沉默的大多数》、《一只特立独行的猪》" const iterator = message.matchAll(/(?<符号1>《)(?<书名>.+?)(?<符号2>》)/ig) for (const item of iterator) { // console.log(item) // console.log(`${item[1]}、${item[2]}、 ${item[3]}`) // 通过索引的方式去记录捕获组不够清晰明了 console.log( item.groups['书名'], item.groups['符号1'], item.groups['符号2'] ) // 直接通过 ?<name> 命名组的方式 } // 黄金时代 《 》 // 沉默的大多数 《 》 // 一只特立独行的猪 《 》非捕获组:
- 有时我们需要括号才能正确应用量词,但我们不希望它们的内容出现在结果中
- 可以通过**在开头添加 **
?:来排除组
jsconst message = "我最喜欢的两本书: 《黄金时代》和《沉默的大多数》、《一只特立独行的猪》" const iterator = message.matchAll(/(?:《)(?<书名>.+?)(?<符号2>》)/ig) for (const item of iterator) { // console.log(item) console.log( `${item[0]}、${item[1]}、${item[2]}` ) // item中已经排除"《 "这个捕获组了 } // 《黄金时代》、黄金时代、》 // 《沉默的大多数》、沉默的大多数、》 // 《一只特立独行的猪》、一只特立独行的猪、》or是正则表达式中的一个术语,实际上是一个简单的“或”- 在正则表达式中,它用竖线
|表示 - 通常会和捕获组一起来使用,在其中表示多个值
jsconst info = "x3py3za3bmc" console.log( info.match(/x3|y3|a3/g) ) // ['x3', 'y3', 'a3']- 在正则表达式中,它用竖线
三. 正则练习-歌词解析
歌词解析:
http://123.207.32.32:9001/lyric?id=167876jsfunction parseLyric(lyricsString) { const lyricLines = [] // 1.根据\n切割字符串 const lyricsLineString = lyricsString.split('\n') // 2.针对每一行歌词进行解析 const timeRegex = /\[(?<minute>\d{2}):(?<second>\d{2})\.(?<millisecond>\d{2,3})\]/i for (const item of lyricsLineString) { const timeString = item.match(timeRegex) if (!timeString) continue const minute = timeString.groups.minute const second = timeString.groups.second const millisecond = timeString.groups.millisecond // 3.拿到总的毫秒数 const time = minute * 60 * 1000 + second * 1000 + (millisecond.length == 3 ? Number(millisecond) : millisecond * 10) // 4.获取内容 const content = item.replace(timeRegex, '').trim() // 5. 放入数组 lyricLines.push({time, content}) } return lyricLines }数据
jsconst lyricsString = { "sgc": false, "sfy": false, "qfy": false, "lrc": { "version": 26, "lyric": "[00:00.000] 作词 : 许嵩\n[00:01.000] 作曲 : 许嵩\n[00:02.000] 编曲 : 许嵩\n[00:22.240]天空好想下雨\n[00:24.380]我好想住你隔壁\n[00:26.810]傻站在你家楼下\n[00:29.500]抬起头数乌云\n[00:31.160]如果场景里出现一架钢琴\n[00:33.640]我会唱歌给你听\n[00:35.900]哪怕好多盆水往下淋\n[00:41.060]夏天快要过去\n[00:43.340]请你少买冰淇淋\n[00:45.680]天凉就别穿短裙\n[00:47.830]别再那么淘气\n[00:50.060]如果有时不那么开心\n[00:52.470]我愿意将格洛米借给你\n[00:55.020]你其实明白我心意\n[00:58.290]为你唱这首歌没有什么风格\n[01:02.976]它仅仅代表着我想给你快乐\n[01:07.840]为你解冻冰河为你做一只扑火的飞蛾\n[01:12.998]没有什么事情是不值得\n[01:17.489]为你唱这首歌没有什么风格\n[01:21.998]它仅仅代表着我希望你快乐\n[01:26.688]为你辗转反侧为你放弃世界有何不可\n[01:32.328]夏末秋凉里带一点温热有换季的颜色\n[01:41.040]\n[01:57.908]天空好想下雨\n[01:59.378]我好想住你隔壁\n[02:02.296]傻站在你家楼下\n[02:03.846]抬起头数乌云\n[02:06.183]如果场景里出现一架钢琴\n[02:08.875]我会唱歌给你听\n[02:10.974]哪怕好多盆水往下淋\n[02:15.325]夏天快要过去\n[02:18.345]请你少买冰淇淋\n[02:21.484]天凉就别穿短裙\n[02:22.914]别再那么淘气\n[02:25.185]如果有时不那么开心\n[02:27.625]我愿意将格洛米借给你\n[02:30.015]你其实明白我心意\n[02:33.327]为你唱这首歌没有什么风格\n[02:37.976]它仅仅代表着我想给你快乐\n[02:42.835]为你解冻冰河为你做一只扑火的飞蛾\n[02:48.406]没有什么事情是不值得\n[02:52.416]为你唱这首歌没有什么风格\n[02:57.077]它仅仅代表着我希望你快乐\n[03:01.993]为你辗转反侧为你放弃世界有何不可\n[03:07.494]夏末秋凉里带一点温热\n[03:11.536]\n[03:20.924]为你解冻冰河为你做一只扑火的飞蛾\n[03:26.615]没有什么事情是不值得\n[03:30.525]为你唱这首歌没有什么风格\n[03:35.196]它仅仅代表着我希望你快乐\n[03:39.946]为你辗转反侧为你放弃世界有何不可\n[03:45.644]夏末秋凉里带一点温热有换季的颜色\n" }, "klyric": { "version": 0, "lyric": "" }, "tlyric": { "version": 0, "lyric": "" }, "code": 200 } // <script src="./tools/parseLyrics.js"></script> 引入 const result = parseLyric(lyricsString.lrc.lyric) console.log(result) // 拿到存储许多如此{time:xxx, content:xxx}对象的数组
四. 正则练习-日期格式化
时间格式化:从服务器拿到时间戳,转成想要的时间格式
jsconst timeStamp = + new Date() function formatDate(timeStamp, formatString) { const date = new Date(timeStamp) const timeObj = { 'y+': date.getFullYear(), 'M+': date.getMonth() + 1, 'd+': date.getDate(), 'h+': date.getHours(), 'm+': date.getMinutes(), 's+': date.getSeconds() } for (const key in timeObj) { const keyRegExp = new RegExp(key) if (keyRegExp.test(formatString)) { const value = String(timeObj[key]).padStart(2, '0') formatString = formatString.replace(keyRegExp, value) } } return formatString } console.log(formatDate(timeStamp, 'yyyy-MM-dd hh:mm:ss')) // 2022-07-13 00:09:48 console.log(formatDate(timeStamp, 'hh:mm:ss yyyy/MM/dd')) // 00:09:48 2022/07/13TS版本:typescriptconst timeStamp = +new Date() const dateUTC = '2021-08-20T04:07:23.000Z' interface ITimeObj { [index: string]: number } export default function formatDate( dateString: number | string, formatString = 'yyyy-MM-dd hh:mm:ss' ): string { const date = new Date(dateString) const timeObj: ITimeObj = { 'y+': date.getFullYear(), 'M+': date.getMonth() + 1, 'd+': date.getDate(), 'h+': date.getHours(), 'm+': date.getMinutes(), 's+': date.getSeconds() } for (const key in timeObj) { const keyRegExp = new RegExp(key) if (keyRegExp.test(formatString)) { // padStart(n, m):字符串不足n位,从左侧开始填充m字符直至满足n位 const value = String(timeObj[key]).padStart(2, '0') formatString = formatString.replace(keyRegExp, value) } } return formatString } console.log( formatDate(timeStamp) ) // 2022-07-13 00:09:48 console.log(formatDate( dateUTC, 'hh:mm:ss yyyy/MM/dd') ) // 00:09:48 2022/07/13